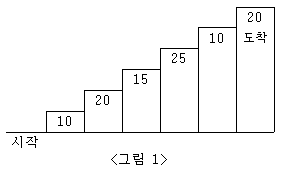
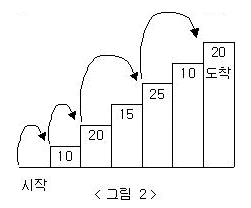
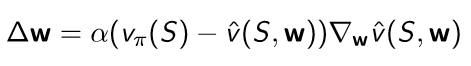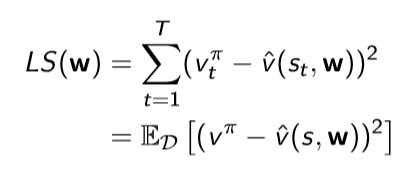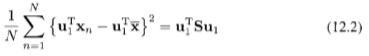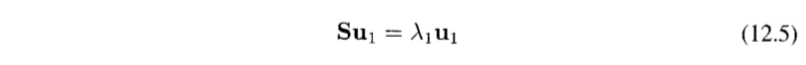N*M 크기의 직사각형이 있다. 각 칸은 한 자리 숫자가 적혀있다. 이 직사각형에서 꼭짓점에 쓰여 있는 수가 모두 같은 가장 큰 정사각형을 찾는 프로그램을 작성하시오. 이때, 정사각형은 행 또는 열에 평행해야 한다.
입력:
첫째 줄에 N과 M이 주어진다. N과 M은 50보다 작거나 같은 자연수이다. 둘째 줄부터 N개의 줄에 수가 주어진다.
출력:
첫째 줄에 정답 정사각형의 크기를 출력한다.
풀이방법:
N과 M의 크기가 50보다 작기 때문에 브루트 포스로 전부 탐색을 해도 된다. 1x1의 정사각형은 반드시 존재하기 때문에 넘어가고 가로, 세로 길이가 2인 정사각형부터 탐색을 시작한다. 한 변의 길이가 n이지만 좌표상의 차이는 n-1이 나게 된다. 따라서 이 점을 이용해서 꼭짓점의 값들이 같은지 탐색하고 같다면 answer를 변경하도록 한다.
만약 모두 탐색을 했는데 초기 answer이 변하지 않는다면 가장 큰 정사각형은 1x1이므로 1을 출력하도록 한다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
n,m=map(int,input().split())
numbers=[]
for _ inrange(n):
numbers.append(input())
dif=1
answer=0
while True:
for i inrange(n-dif):
for j inrange(m-dif):
if numbers[i][j]==numbers[i][j+dif]==numbers[i+dif][j]==numbers[i+dif][j+dif]:
우리 나라는 가족 혹은 친척들 사이의 관계를 촌수라는 단위로 표현하는 독특한 문화를 가지고 있다. 이러한 촌수는 다음과 같은 방식으로 계산된다. 기본적으로 부모와 자식 사이를 1촌으로 정의하고 이로부터 사람들 간의 촌수를 계산한다. 예를 들면 나와 아버지, 아버지와 할아버지는 각각 1촌으로 나와 할아버지는 2촌이 되고, 아버지 형제들과 할아버지는 1촌, 나와 아버지 형제들과는 3촌이 된다.
여러 사람들에 대한 부모 자식들 간의 관계가 주어졌을 때, 주어진 두 사람의 촌수를 계산하는 프로그램을 작성하시오.
입력:
사람들은 1, 2, 3, ..., n (1<=n<=100)의 연속된 번호로 각각 표시된다. 입력 파일의 첫째 줄에는 전체 사람의 수 n이 주어지고, 둘때 줄에는 촌수를 계산해야 하는 서로 다른 두 사람의 번호가 주어진다. 그리고 셋째 줄에는 부모 자식들 간의 관계의 개수 m이 주어진다. 넷째 줄부터는 부모 자식간의 관계를 나타내는 두 번호 x,y가 각 줄에 나온다. 이때 앞에 나오는 번호 x는 뒤에 나오는 정수 y의 부모 번호를 나타낸다.
각 사람의 부모는 최대 한 명만 주어진다.
출력:
입력에서 요구한 두 사람의 촌수를 나타내는 정수를 출력한다. 어떤 경우에는 두 사람의 친척 관계가 전혀 없어 촌수를 계산할 수 없을 때가 있다. 이 때에는 -1을 출력해야 한다.
풀이방법:
두 사람이 얼마나 긴 간격으로 연결되어 있는지 확인하는 문제이기 때문에 dfs나 bfs로 풀어야 할 것 같다고 생각했다. dfs로도 풀 수 있는지 정확히 모르지만, 두 사람 사이의 몇 level(단계)가 있는지 확인하면 되는 문제 이므로 bfs를 사용하기로 했다.
형제들 같은 경우에는 2촌으로 계산되는데 그 이유가 (나에서 부모님으로 1촌) + (부모님에서 형제로 1촌) 이기 때문이다. 따라서 이러한 관계를 알기 위해서는 양방향으로 이동할 수 있도록 relation을 만들었고, 중복방문을 하지 않기 위해서 visited를 만들었다.
처음 시작해야 하는 사람의 번호로 시작한다. 그리고 그 사람과 관계가 있는 사람들 중 방문하지 않았던 사람만 temp라는 배열에 담고 방문한 것으로 visited를 변경한다. 그리고 이 temp에 나와의 관계가 알고 싶은 사람의 번호가 있는지 확인하고, 있다면 break 없다면 temp의 길이를 재서 탐색할 사람이 있는지 확인한다. temp에 더 탐색할 사람이 있다면 위의 행동을 다시 반복하고, 더 이상 탐색할 사람이 없다면 친척 관계가 전혀 없다는 것으로 출력하면 된다.
그리고 최종 출력에서 +1을 했는데, 이 이유는 temp에 내가 원하는 사람의 번호가 있기 때문에 그 관계로 이동한다는 행동이 빠져있었기 때문에 +1을 해서 출력하도록 했다.
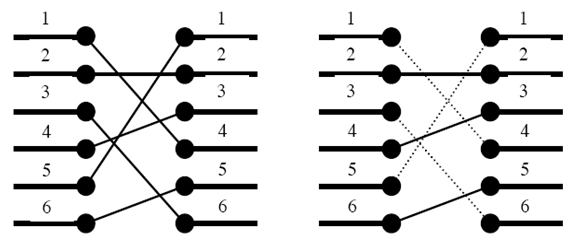
예를 들어 왼쪽 그림이 n개의 포트와 다른 n개의 포트를 어떻게 연결해야 하는지를 나타낸다. 하지만 이와 같이 연결을 할 경우에는 연결선이 서로 꼬이기 때문에 이와 같이 연결할 수 없다. n개의 포트가 다른 n개의 포트와 어떻게 연결되어야 하는지가 주어졌을 때, 연결선이 서로 꼬이지(겹치지, 교차하지) 않도록 하면서 최대 몇 개까지 연결할 수 있는지를 알아내는 프로그램을 작성하시오.
입력:
첫째 줄에 정수 n(1<=n<=40,000)이 주어진다. 다음 줄에는 차례로 1번 포트와 연결되어야 하는 포트 번호, 2번 포트와 연결되어야 하는 포트 번호, ... , n번 포트와 연결되어야 하는 포트 번호가 주어진다. 이 수들은 1 이상 n 이하이며 서로 같은 수는 없다고 가정하자.
출력:
첫째 줄에 최대 연결 개수를 출력한다.
풀이방법:
복잡해 보이지만 LIS 문제라고 생각하면 쉽게 풀 수 있다. LIS를 푸는 방법에는 여러 가지가 있지만 가장 대표적인 방법인 DP를 사용해서 문제를 풀어보았다.
여기서 O(NlogN)이 두 개 있었는데 lower_bound는 python의 bisect를 쓰면 될 것 같다. 이번에는 인덱스 트리를 사용해서 문제를 풀어 보았다. 인덱스 트리를 만들기 위한 과정에서 시간이 많이 소요 되는 것 같아서 이 역시도 pypy3로 통과했다. 아마도 bisect를 사용하면 python으로도 통과할 수 있을 것 같다.
Youtube에 있는 David Silver의 Reinforcement Learning 강의를 보고 작성하였습니다.
6. Value Function Approximation
지금까지는 Grid World를 통해서 작은 상황을 설정했고 table로 저장하는 것이 가능했다. 그리고 value function과 policy를 구하는 과정을 살펴보았다. 이러한 문제들을 Tabular Method라고 부른다. 하지만 실제 문제에 대해서 강화학습을 적용하기에는 너무 크다.
지금 강화학습으로 해결할 수 있거나 해결하려고 하는 문제에 대해서 state의 갯수를 알아보면 다음과 같다. Backgammon은 1020, 알파고는 10170, 헬리콥터(자율주행)은 사실상 무한대의 상태들을 가지고 있다. 따라서 이러한 문제에 대해서 value function과 policy를 구하고자 하는 것은 어렵다. 따라서 이 값들을 추정하는 방법들에서 배우도록 한다.
function approximation을 하는 방법은 어렵지 않다. 새로운 변수 w를 대입해서 이 변수가 table의 정보를 대변하도록 만들면 된다. 즉 다음과 같이 함수화 할 수 있다.
w는 학습을 통해서 update하며, true value와 근사하도록 맞춰나간다. 최근에는 이 학습을 하는 과정에 deep learning을 사용하기도 한다.
Value Function Approximation에는 다음과 같은 종류들이 있다고 한다.
function approximator에는 여러 개가 있지만 그 중 미분가능한 Linear combinations of features, Neural network를 이번 장에서 소개하도록 한다. 그리고 이들은 non-stationary, non-iid한 data라고 하는데, 분포가 계속해서 바뀌며 독립적이지 않다.
Incremental Methods
w를 업데이트를 하는 방법중 가장 좋은 것은 Gradient Descent이다. 이 방법은 간단하고 프로그램 상으로도 강력하다. 하지만 시작점에서 조금만 달라져도 다른 점에 도착할 수 있고, 이 점이 local optima일 수도 있다.
w로 표현되는 loss function인 J(w)는 true value와의 error로써 이를 최소화하는 것이 목적이다.
이를 미분해서 값을 update 할 수 있는데 expectation을 쓰는 방법과 sampling을 하는 방법이 있고 다음과 같다.
MC와 TD에서 했던 것처럼 vπ(S)를 대체해서 사용할 수 있다.
MC with Value Function Approximation
MC의 Gt는 unbiased 하고, true value의 noisy sample이다. 그러므로 training data를 지도학습으로 적용할 수 있다. 그래서 위와 같이 사용가능하며, local optimum으로 수렴하게 된다. 그리고 non-linear한 경우에도 적용할 수 있다고 한다.
TD Learning with Value Function Approximation
TD-target은 guess를 사용하는 것이기 때문에 true value의 biased sample이다. 하지만 여전히 training data를 지도학습으로 적용이 가능하고 위에서 소개한 것처럼 TD(0)를 적용할 수 있다.
Linear TD(0)는 (거의) global optimum에 수렴한다.
TD(λ) with Value Function Approximation
Gtλ도 true value의 biased sample이다. 그러므로 역시 training data를 지도학습으로 적용할 수 있으며 Forward view linear TD(λ), Backward view linear TD(λ)로 각각 적용할 수 있고, 서로 equivalent하다.
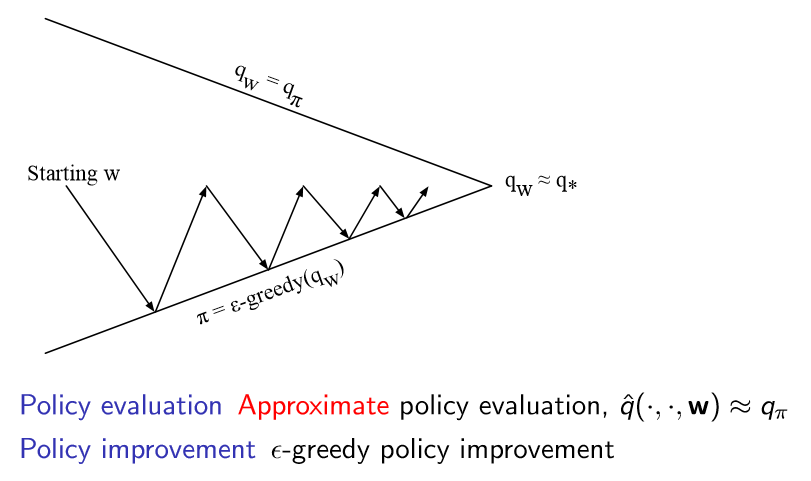
Control with Value Function Approximation
하지만 value function을 사용하면 control 문제를 다룰 때 발생했던 model-free가 발생한다. 따라서 이번에도 value function을 q-function으로 바꾸도록 한다.
그리고 그 뒤로는 value function을 했던 내용과 동일합니다.
Batch Methods
Gradient descent는 간단하고 매력적이지만 한번 쓰고 버린다. 따라서 sample efficient하지 않다고 한다. 따라서 Batch method는 1000개의 데이터가 있으면 그 중 10개를 sample로 해서 사용하는 방식이다. 이를 통해 value function의 best fitting을 찾을 수 있다고 한다.
value function approximation을 사용하고, experience D는 <state, value>의 쌍으로 구성된다. 이 때 best fitting value인 파라미터 w를 찾기 위해서 Least squares 알고리즘을 사용한다.
Least squares 알고리즘은 추측값과 참값 사이의 sum-squared error를 최소화하는 w를 찾는 알고리즘이다.
Stochastic Gradient Descent with Experience Replay
<state, value>로 쌍이 묶어진 experience D가 있을 때, 다음을 반복한다.
그러면 이는 다음과 같이 수렴한다.
이러한 방법을 Experience replay라고 하며 강화학습에서 자주 사용하는 방법이다.
Experience replay in Deep Q Networks
Non-linear랑 off-policy일 때 학습을 진행하면 수렴을 하지 않고 발산한다는 문제점이 발생한다. 따라서 이러한 문제를 해결하기 위해 DQN은 experience replay와 fixed Q-target을 사용한다고 한다.
Experience reaply: 어떤 action에 어떤 reward와 그 state등 정보들이 있는 transition을 replay memory에 저장하고, random하게 mini batch를 뽑는다. 그리고 MSE를 통해 학습한다.
Fixed Q-target: target을 계산할 때에 예전 parameter를 쓰는 것, 두 개의 파라미터 set이 있다. 하나는 고정시키고 다른 하나는 업데이트 중인 파라미터 set을 가진다. non-linear 함수일 때에 업데이트 방향이 계속 바뀌기 때문에 수렴되기 어렵다. 따라서 1000번 정도는 고정된 parameter set을 사용하며 진행하다가 그 이후에 고정된 parameter set을 업데이트 하던 parameter set으로 바꾼다. 예전 버전을 w-, 현재 버전을 w라 했을 때, target에서는 고정된 것을 사용하기 때문에 fixed Q-target이라 한다.
1742년, 독일의 아마추어 수학가 크리스티안 골드바흐는 레온하르트 오일러에게 다음과 같은 추측을 제안하는 편지를 보냈다.
4보다 큰 모든 짝수는 두 홀수 소수의 합으로 나타낼 수 있다.
예를 들어 8은 3+5로 나타낼 수 있고, 3과 5는 모두 홀수인 소수이다. 또, 20 = 3 +17 = 7+13, 42 = 5+37 = 11+ 31 = 13 + 29 = 19 +23 이다.
이 추측은 아직도 해결되지 않은 문제이다. 백만 이하의 모든 짝수에 대해서, 이 추측을 검증하는 프로그램을 작성하시오.
입력:
입력은 하나 또는 그 이상의 테스트 케이스로 이루어져 있다. 테스트 케이스의 개수는 100,000개를 넘지 않는다.
각 테스트 케이스는 짝수 정수 n 하나로 이루어져 있다. (6 <= n <=1000000)
입력의 마지막 줄에는 0이 하나 주어진다.
출력:
각 테스트 케이스에 대해서, n = a+b 형태로 출력한다. 이때, a와 b는 홀수 소수이다. 숫자와 연산자를 공백 하나로 구분되어져 있다. 만약, n을 만들 수 있는 방법이 여러 가지라면, b-a가 가장 큰 것을 출력한다. 또, 두 홀수 소수의 합으로 n을 나타낼 수 없는 경우에는 "Goldbach's conjecture is wrong"을 출력한다.
풀이방법:
여러 케이스에서 소수를 사용해야 하는데, 그 때마다 계산을 해야 하는 소수들을 구하면 너무 오랜 시간이 걸리기 때문에 최대 1,000,000를 넘지 않는다는 것을 이용해서 미리 소수들을 구하도록 한다.
따라서 소수를 효율적으로 구할 수 있는 방법 중 하나인 에라토스테네스의 체 방법을 사용해서 배열을 구한다. 그 뒤로는 입력으로 들어온 n 이하에 존재하는 소수들에 대해서 합을 구해본다. 이 때 n//2까지만 반복문을 돌아도 되는데, 그 뒤에 있는 값들은 이미 이 전에 검사했을 것이기 때문이다. (ex) 3+5=8, 5+3=8)
그리고 두 수간의 차이가 가장 큰 경우를 출력해야 하므로 작은 수부터 즉 3부터 확인을 하며 처음으로 추측을 만족시킬 때가 간격이 가장 크기 때문에 break를 걸고 형식에 맞게 출력을 하도록 한다.
원래는 추측이 틀렸을 때에는 지정된 문구를 출력해야 하지만, 이 추측은 실제로 존재하며 아직 반례를 찾지 못했기 때문에 틀린 경우가 없기 때문에 생략했다.