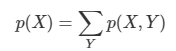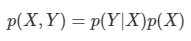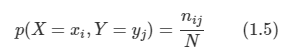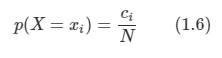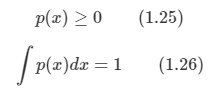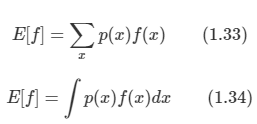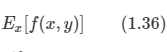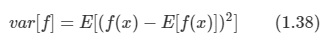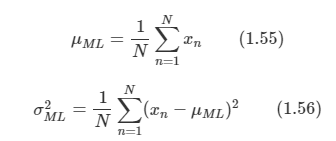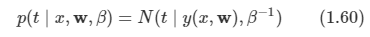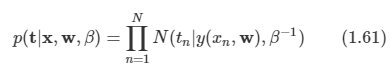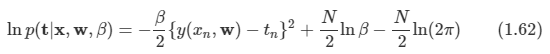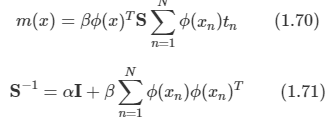*Youtube에 있는 David Silver의 Reinforcement Learning 강의를 보고 작성하였습니다.
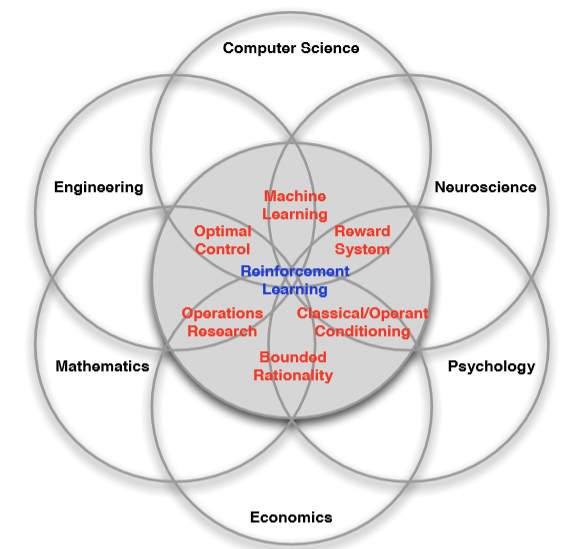
강화학습은 여러 분야에서 사용가능하다. 컴퓨터 과학, 공학, 수학, 경제학 등 여러 분야에서 사용 가능하다.
-
머신러닝은 지도 학습, 비지도 학습, 강화 학습 세 분야로 나눌 수 있는데, 강화 학습에 대해 자세히 알아보도록 한다.
-
강화학습이 다른 머신러닝 분야들과 다른점은 무엇일까?
- supervisor가 존재 하지 않는다.(y 값이 존재하지 않는다.) 대신 reward라는 값이 존재한다.
- Feedback을 바로 받는 것이 아니라 일련의 행동들이 모두 마친 뒤에 나타난다.
- 내가 이전에 한 행동에 따라 결과가 바뀌게 된다. 즉 시점에 따라 행동이 다르다.
- agent의 행동에 따라 얻는 데이터가 달라지게 된다. (agent는 뒤에 다시 소개한다.)
-
강의에서 다음과 같은 예시들을 소개하고 있다.
- Fly stunt manoeuvres in a helicopter(자율주행)
- Defeat the world champion at Backgammon(유럽의 보드게임)
- Manage an investment portfolio(주식)
- Control a power station(발전소 관리)
- Make a humanoid robot walk(로봇이 걷도록 하는것)
- Play many different Atari games better than humans(알파고(Atari 게임))
-
Reward (Rt)
- scalar 피드백 값, 얼마나 agent가 t 단계에서 잘 수행했는지를 나타낸다.
- agent의 임무는 누적 보상을 최대화 하는 것.
- 강화 학습은 reward hypothesis에 기반을 두고 있다.
- reward hypothesis?
- 기대 누적 보상을 최대화하는 것이 agent의 목표이다.
- reward hypothesis?
-
Sequential Decision Making
- Goal : 총 reward를 최대화 하는 행동을 고르는 것.
- 행동은 긴 기간 동안 연속적으로 발생하며 보상은 이 행동들이 마친 뒤에 얻게 된다.
- 이로써 나중에 더 큰 보상을 얻을 수 있다면 지금 당장은 적은 보상을 선택하거나 손해를 볼 수도 있음을 의미한다.
Agent and Environment

- agent
- environment의 observation, reward를 받아서 agent가 action을 수행한다.
- Environment
- agent의 action을 받아서 바뀐 observation, reward를 agent에 전달해준다.
즉 agent는 사람, envionment는 지구로써 사람이 어떤 행위를 취하면 지구에 영향을 주게 되고 지구의 환경에 변하며 이는 다시 사람에게 영향을 주게 된다.(지구 온난화?)
History and State
- history는 observation, actions, rewards를 일련적으로 표현한 것.

- state는 다음에 어떤 것을 해야 하는지 결정에 도움을 주는 정보, 이 것은 history에 특정한 함수를 취함으로써 얻는다.
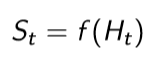
Environment state and Agent State
agent, environment가 각각 가지고 있는 상태, 정의상으로는 agent state는 알고 있지만 envionment state는 모른다.( ex) 사람은 자신의 정보를 바탕으로 행동을 하지만, 그렇다고 지구의 환경이 어떻게 변할지는 예측할 수 없다.(또는 매우 힘들다)
Markov state(information state)

'Markov하다' 라는 정의로 미래는 과거에 어떤 상태였는지는 관계 없이 현재 상태만이 영향을 준다는 것이다. 다음 강의에서 Markov에 대해서 자세히 설명하기 때문에 이번엔 정의만 보고 넘어간다.
- Full observability : agent가 agent state, environment state를 모두 아는 것, 이러한 경우에 Markov decision Process라고 부르며 다음 강의에서 자세히 다룬다.
RL's major components
- Policy
- agent의 행동을 의미한다. 어떤 현재 상태에 있을 때 어떠한 행동을 할지를 나타낸다.
- 결정론적 정책
- 상태 s에 도달하면 항상 a라는 행동을 한다.
- 통계학적 정책
- 상태 s에 있을 때 일정한 확률에 따라 특정한 행동 a를 한다.
- Value Function
- 미래 reward의 예측을 하는데 사용한다.
- 이 값으로 상태가 좋은지/나쁜지 판단할 수 있다.
- Model
- 환경에 다음에 어떠한 것을 할 지 예측하는 것
- 즉 다음에 어떤 상태가 발생되고, reward가 발생하는지 알려준다.
Categorizing RL agent
- Value Based
- Value Function
- Policy Based
- Policy
- Actor Critic
- Policy
- Value Function
- Model Free
- Policy and Value Function
- Model Based
- Policy and Value Function
- Model

Learning and Planning
- Reinforcement Learning
- 환경은 초기에 알려져 있지 않다.
- agent는 환경과 상호작용한다.
- agent는 정책을 발전시킨다.
- Planning
- 환경의 모델을 알고 있다.
- agent는 그 모델에서 계산을 수행한다.
- agent는 정책을 발전 시킨다.
Exploration and Exploitation
- Exploration(탐험)
- 탐험은 전체 공간을 골고루 찾아보는 전략이며 항상 같은 방향으로 진행하지 않는다.
- Exploitation(탐사)
- 탐사는 특정한 곳 주위를 집중적으로 찾아보는 전략으로 보상이 최대화 되는 방향으로만 진행한다.
- 이들은 trade-off 관계에 있으며, 탐험은 시간이 너무 오래 걸리고, 탐사는 지역 최적해에 머무는 문제가 발생한다.
https://www.youtube.com/watch?v=2pWv7GOvuf0&list=PLqYmG7hTraZDM-OYHWgPebj2MfCFzFObQ
'Book > Reinforcement Learning' 카테고리의 다른 글
| [RL]Lecture 5. Model-Free Control (0) | 2020.02.12 |
|---|---|
| [RL]Lecture 4. Model-Free Prediction (0) | 2020.02.05 |
| [RL]Lecture 3. Planning by Dynamic Programming (1) | 2020.01.29 |
| [RL]Lecture 2. Markov Decision Processes (0) | 2020.01.22 |
| [RL]ch 0. Intro (0) | 2020.01.15 |