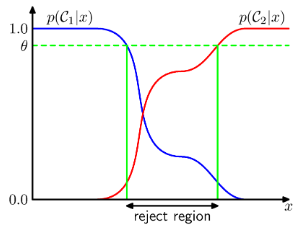
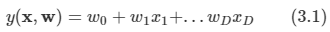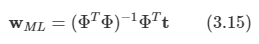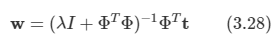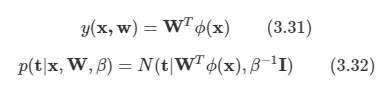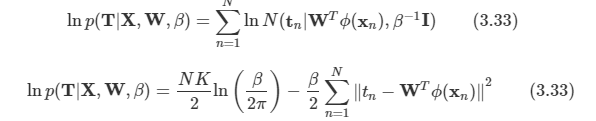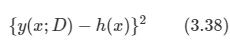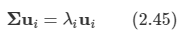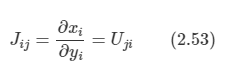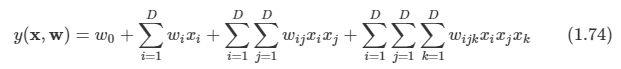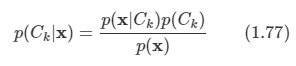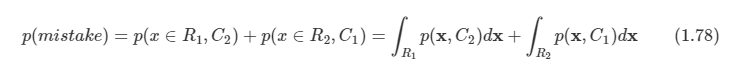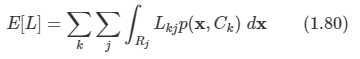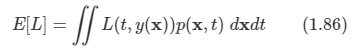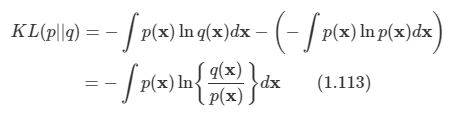2.1 Introduction
이전 장에서는 확률이 어떻게 머신 러닝에서 사용될 수 있는지 살펴보았다면, 2장에서는 더 자세한 확률 이론에 대해 알아본다. 확률에 대한 기술적인 논의를 하기 전에, "확률이란 무엇인가?"라는 질문에 먼저 답해보도록 한다. 쉽게 생각할 수 있는 주제로 '동전을 던졌을 때, 앞면이 나올 확률은 0.5'라는 것은 다들 알 것이다. 사실 확률에 대한 해석은 크게 2가지가 가능하다.
- Frequentist
- 빈도주의적인 해석으로써 장기간에 걸쳐 발생 빈도를 의미한다. 즉, 동전을 수없이 많이 던져서 앞면이 나올 확률이 0.5가 나온다는 것을 알 수 있다는 것이다.
- Bayesian
- 베이지안 해석으로 확률은 어떤 것에 대한 불확실성을 수량화하는 것이며, 반복되는 시도보다는 기본적으로 정봐와 연관된 것이다. 즉, 베이지안적 시각으로 보면, 다음 동전 던지기 때에 앞면과 뒷면이 나올 확률은 동일하다는 것이다.
베이지안식 해석의 큰 장점은 장기간의 빈도를 가지지 않는 사건에 대한 불확실성을 모형화하는 것에 사용할 수 있다는 것이다. 따라서 이 책에서는 베이지안식 해석을 채택하여 설명하도록 한다.
2.2 A brief review of probability theory
이 절에서는 확률 이론에 대한 기초 개념을 간단히 리뷰하도록 한다. 따라서 이미 확률 이론에 대해 익숙한 사람이라면 이 절을 생략해도 무관하다.
2.2.1 Discrete random variables

p(A)는 event A가 발생할 확률을 의미한다. 예를 들어, A는 "내일 비가 올 확률"가 될 수 있다. 0<= p(A) <=1 이어야 하며, p(A)=0은 사건이 절대 발생하지 않는다는 것을 의미하고, p(A)=1은 사건이 반드시 발생한다는 것을 의미한다.
이산 확률 변수 X를 정의해서 이항 사건에 대한 개념을 확장할 수 있으며, X는 유한 집합이나 가산 무한 집합으로부터 어떠한 값도 가질 수 있다. X=x의 확률은 p(X=x)로 나타내고, 간단히 p(x)라고 나타낸다. 여기서 p()는 확률 질량 함수 또는 pmf이다.p(x)도 0과 1 사이의 값을 가지며, 총합은 1이 된다는 조건을 만족한다. 위 그림은 유한한 상태 공간에서 정의된 두 개의 pmf며, 왼쪽은 균등 분포를 가지고 있으며, 오른쪽은 퇴화 분포에 해당하며, X가 항상 1과 같다는 것을 표현한다.
2.2.2 Fundamental rules
생략
2.2.3 Bayes rule
조건부 확률의 곱, 합 법칙을 통합하면 Bayes rule을 도출 할 수 있으며, 이를 Bayes Theorem이라고 부른다.

2.2.3.1 Example: medical diagnosis
베이즈 법칙을 사용하는 예로 의학적 진단 문제를 생각해보자. 당신은 40대 여성이라고 가정하고, 유방조열술로 유방암에 대한 의학 검진을 받기로 했다. 검사가 양성일 때, 실제로 암일 확률은 얼마일까?
이 확률을 구하기 위해서는 우선 검사가 얼마나 신뢰성이 있는지 알아야 한다. 검사가 80%의 정확성을 가지고 있을 경우 당신이 암이라면 0.8의 확률로 양성이 나타날 것이다. 즉, 다음과 같다.
p(x=1|y=1) = 0.8
여기서 x=1은 유방조영술이 양성인 사건을 의미하고, y=1은 유방암인 경우의 사건이다. 대부분의 사람들이 이런 경우 80%가 암이라고 결론을 내린다. 하지만 이것은 False다! 이러한 결론은 유방암을 가지고 있는 사전 확률을 무시한 것이다. 다행히도 암을 가질 확률은 매우 낮다.
p(y=1) = 0.004
사전 확률을 무시하는 것을 기저율 에러(base rate fallacy)라고 한다. 또한 테스트가 거짓 양성 또는 거짓 정보일 케이스인 경우도 고려해야 한다. 불행하게도 거짓 양성인 가능성은 높다.
p(x=1|y=0) = 0.1
베이즈 법칙을 사용해 세 개의 조건을 모두 결합하면 다음과 같이 정확한 답을 계산할 수 있다.

즉, 검사가 양성이라면 실제 유방암일 확률은 대략 3%에 해당한다.
2.2.4 Independence and conditional independence
X와 Y의 결합 확률을 곱으로 표현할 수 있다면 무조건적인 독립, 또는 marginally 독립이라고 하며, X⊥Y로 표현한다. 즉, 다음과 같다.

일반적으로 결합 확률이 marginal의 곱이면 변수 집합이 상호 독립적이라고 한다.
대부분의 변수는 다른 변수에게 영향을 주는 경우가 많기 때문에 무조건적인 독립은 매우 드물다. 하지만 이런 영향은 직접적이라기보다는 다른 변수에 의해 중재된다. 그러므로 조건부 결합 확률이 조건부 주변의 곱으로 표현될 수 있는 경우에만 "Z가 주어졌을 때 X와 Y는 조건부 독립이다" 라고 한다.
2.2.5 Continuous random variables

지금까지는 불확실한 이산량에 대한 추정만을 다뤘으며, 이번 절에서는 어떻게 확률을 확장해야 하는지 알아본다.
X를 불확실한 연속량으로 가정한다면, X가 a이상 b이하일 확률은 다음과 같이 계산한다.
위와 같이 확률을 계산하는 것을 함수 형태로 정의하고, 이것을 X의 누적 분포 함수(cumulative distribution function) 혹은 cdf라고 정의한다. 이는 그림 (a)에 해당하고, 표기법을 사용하면 다음과 같다.

이제 도함수를 정의하고, 이것을 확률 밀도 함수(probability density function) 혹은 pdf라고 한다. 이는 그림 (b)에 해당한다. 표기법을 사용하면 다음과 같다.

2.2.6 Quantiles
cdf F가 단조 증가 함수이기 때문에 역함수를 가지고 있다. 이를 F-1라고 하고, F의 분위수(quantile)라고 부른다. F-1(0.5)는 중앙값이고, F-1(0.25), F-1(0.75)는 각각 하위 및 상위 사분위수다.
2.2.7 Meana and variance
분포를 설명할 때 가장 익숙한 속성은 평균 또는 기댓값이며, μ와 같이 표기한다. 분산은 분포의 '흩어진 정도'를 측정하는 것이며 σ2로 표기한다.
2.3 Some common discrete distributions
보편적으로 사용되는 이산 상태 공간에서 정의된 모수적 분포들에 해당한다. 자세하게 설명하지 않고, 분포의 종류들만 나열하도록 한다.
- The binomial and Bernoulli distribuions
- The multinomial and multinoulli distributions
- The Poisson distribution
- The empirical distribution
2.4 Some common continuous distributions
2.3절과 같이 분포들에 대해 나열만 하도록 한다.
- Gaussian distribution
- Degenerate pdf
- The Laplace distribution
- The gamma distribution
- The beta distribution
- Pareto distribution
'Book > Machine Learning' 카테고리의 다른 글
| [Machine Learning]1. Introduction- part.2 (0) | 2022.03.02 |
|---|---|
| [Machine Learning]1. Introduction- part.1 (0) | 2022.02.17 |
| [ML]12. Continuous Latent Variable - part1 (0) | 2020.03.02 |
| [ML]ch 9.Mixture models and EM (0) | 2020.02.24 |
| [ML]ch 4. Linear Models for Classification - part 2 (0) | 2020.02.17 |