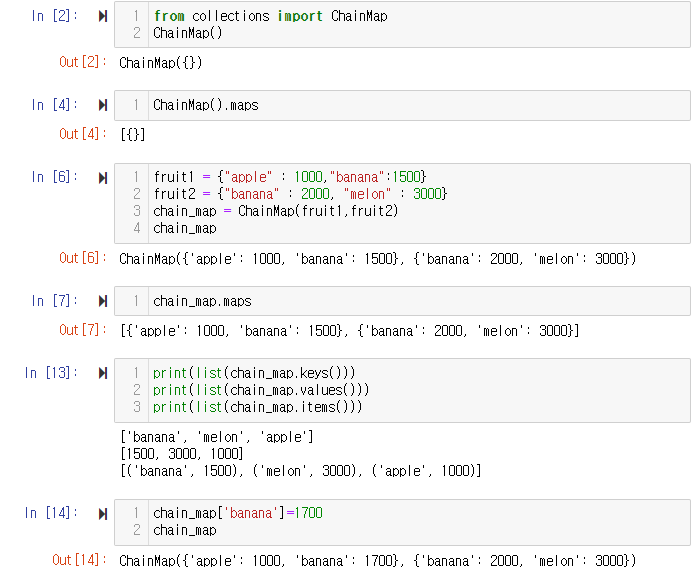
ChainMap
collection 모듈에 있는 ChainMap은 공식문서에 따르면 여러 딕셔너리나 다른 매핑을 묶어 갱신 가능한 단일 뷰를 만든다고 한다.
즉, ChainMap은 여러 딕셔너리를 하나의 링크드 형태로 묶으며, 기존에는 여러 dict들을 for를 통해 탐색했던 것을 한 번에 수행할 수 있다고 생각하면 된다.
chainMap에는 다음과 같은 method들이 있다.
- maps
- new_child
- parents
new_child

parents

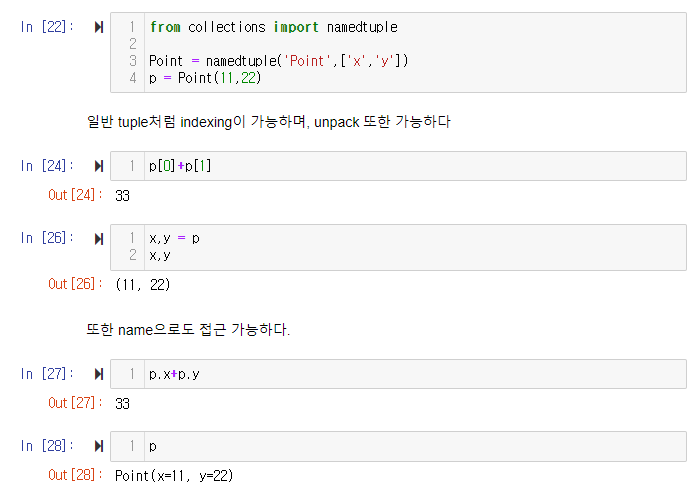
namedtuple
namedtuple은 지정해준 이름으로 간단한 서브 클래스를 반환한다. 이 서브 클래스는 인덱싱되고 iterable일 뿐만 아니라 attribute 조회로 접근 할 수 있다.


Counter
Counter는 hash 가능한 객체를 세기 위한 dict 서브 클래스다. 요소는 dict의 키로 저장되고 개수는 value로 저장된다. 개수는 0이나 음수도 포함하는 임의의 정숫값이 될 수 있다.



OrderedDict
딕셔너리 순서를 기억하는 Dict으로 옛날 python에서는 이를 활용하는 것이 유용했으며, 이제 내장 dict도 삽입 순서를 기억하기 때문에 덜 중요해졌다.
popitem(last=True)
OrderedDict의 popitem()은 (key, value)를 반환하고 제거한다. last가 True면 LIFO 방식으로, False면 FIFO 방식으로 반환다.

defaultdict
defaultDict은 dict과 유사하지만 key값이 없을 경우에 미리 지정해 놓은 초기(default)값을 반환하는 역할을 한다.
dict의 setdefault 와 유사하지만 더 간단하고 빠르다.

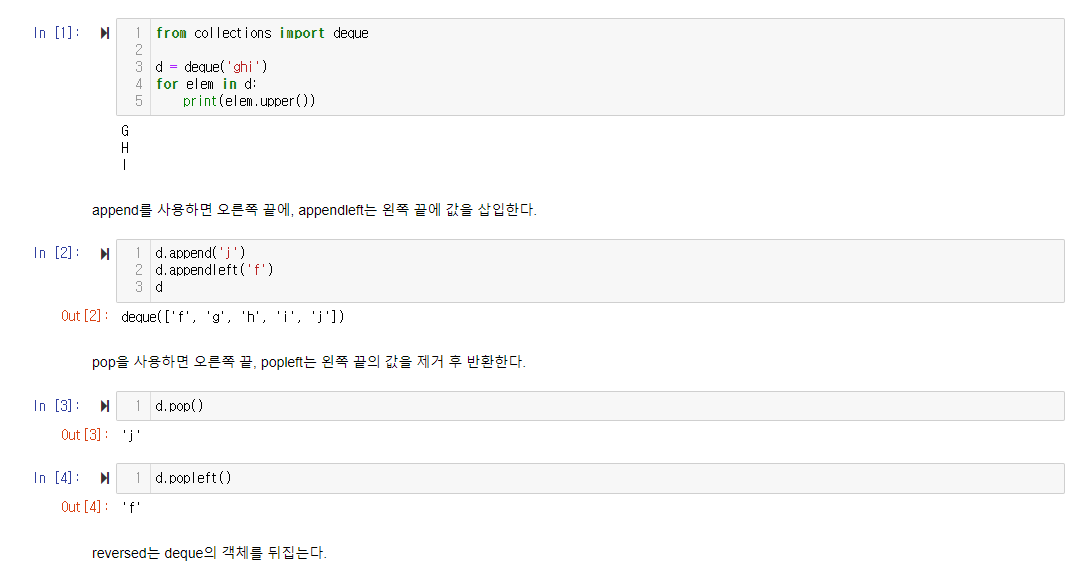
deque
deque는 double-ended-queue의 약자로 stack과 queue를 일반화한 것이다. deque는 메모리적으로 효율적이기 때문에 양쪽 끝에서 append와 pop이 모두 O(1)의 성능을 지원한다. deque는 다음과 같은 메서드를 지원한다.
- append
- appendleft
- clear
- copy
- count(x)
- extend
- extendleft
- index
- insert
- pop
- popleft
- remove
- reverse
- rotate
이 중 자주 쓰이는 것들만 살펴본다.
deque를 사용해서 iterable한 객체를 deque 객체로 만들 수 있다.

https://docs.python.org/ko/3/library/collections.html
collections — 컨테이너 데이터형 — Python 3.9.6 문서
collections — 컨테이너 데이터형 소스 코드: Lib/collections/__init__.py 이 모듈은 파이썬의 범용 내장 컨테이너 dict, list, set 및 tuple에 대한 대안을 제공하는 특수 컨테이너 데이터형을 구현합니다. named
docs.python.org
'Language > Python' 카테고리의 다른 글
| [Python] Functools 모듈 (0) | 2021.07.16 |
|---|---|
| [Python 따라하기]10. 내장함수와 외장함수(filter,map,random) (0) | 2019.04.02 |
| [Python 따라하기]9.예외처리(try,except,finally) (0) | 2019.03.26 |
| [Python 따라하기]8.클래스와 상속(Class, inheritance) (2) | 2019.03.19 |
| [Python 따라하기]7.파일 입출력 (File I/O) (0) | 2019.03.12 |
















































 file_example.txt
file_example.txt


























































