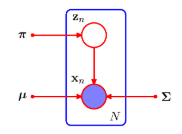
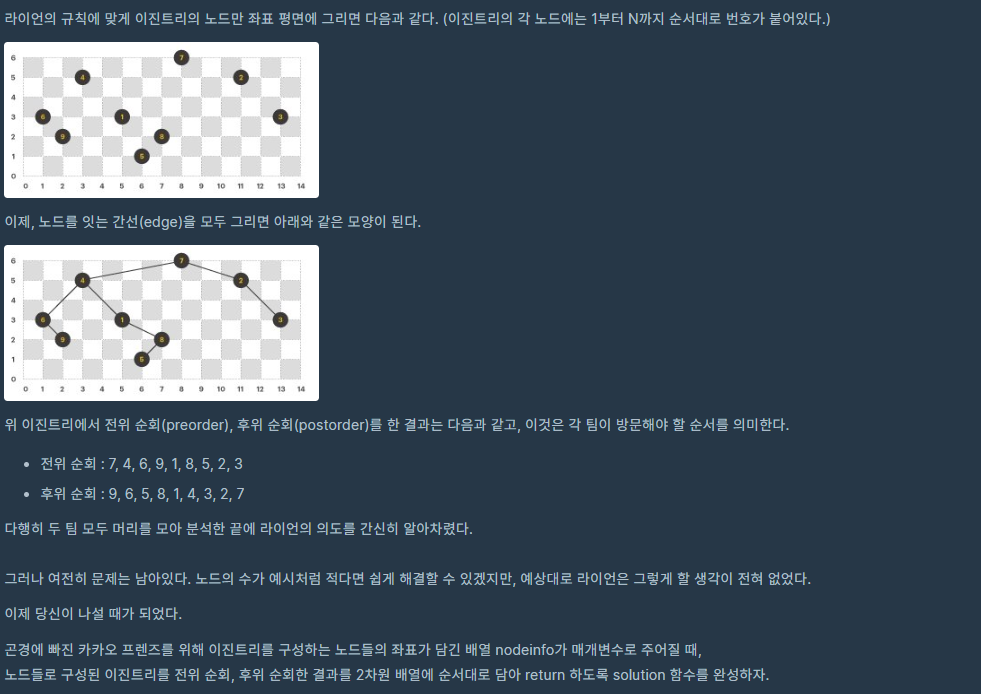
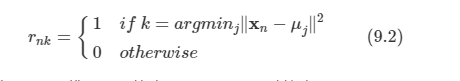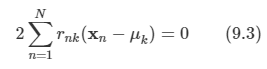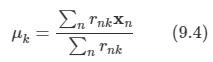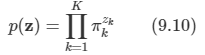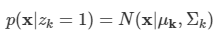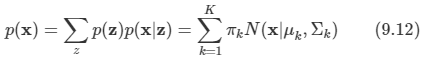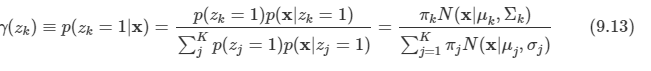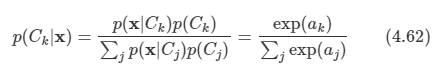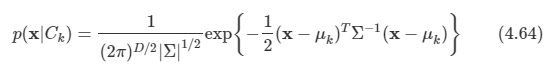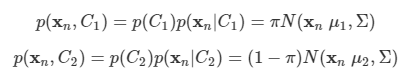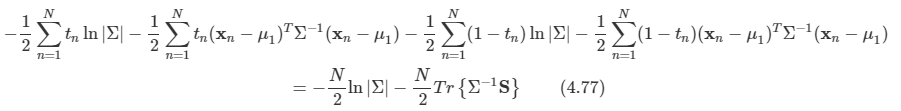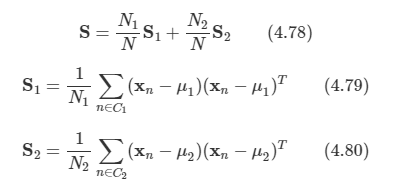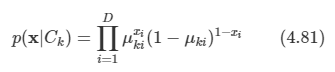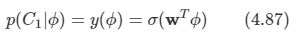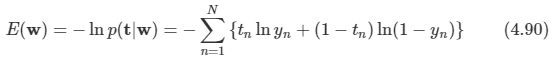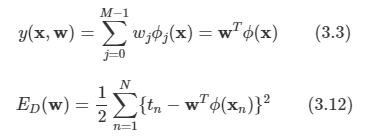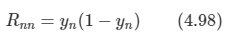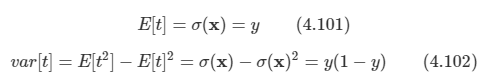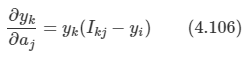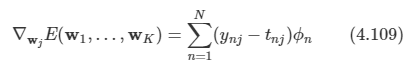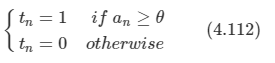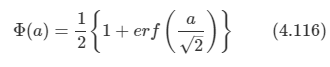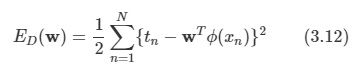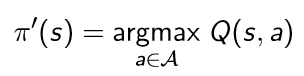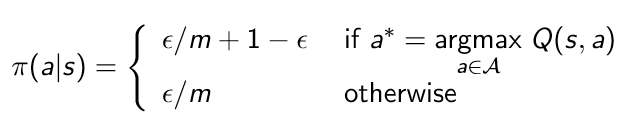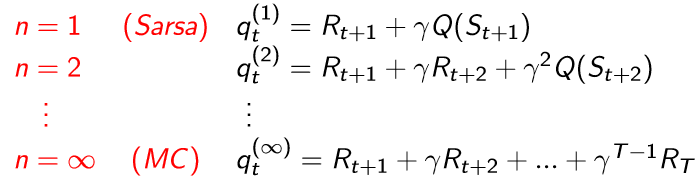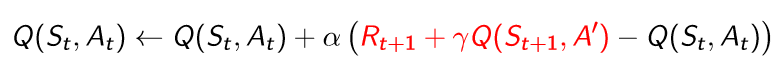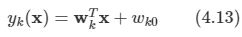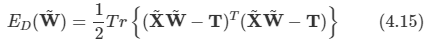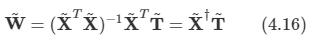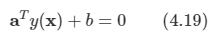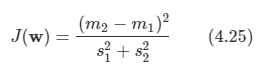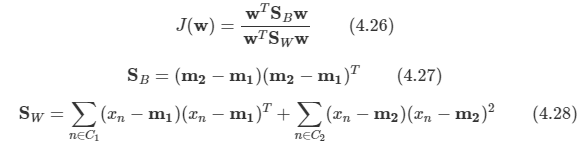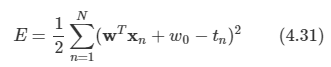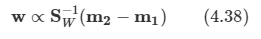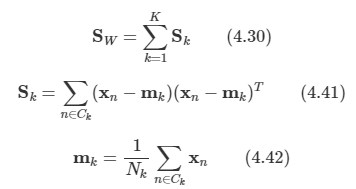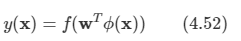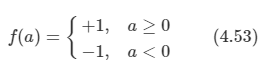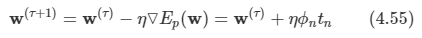문제:

풀이방법:
트리 구조를 알고 있는지 물어보는 문제인 것 같다. 따라서 Tree라는 class를 만들고, 이 클래스는 x,y 좌표와 left, right를 만들어서 node 연결을 하도록 한다.
우선 부모 노드를 찾고, 자식 노드들을 알기 위해서 정렬을 하는 작업을 먼저 한다. y가 큰 순으로, x가 작은 순으로 정렬하도록 하기 위해 sorted의 key를 사용하였다.
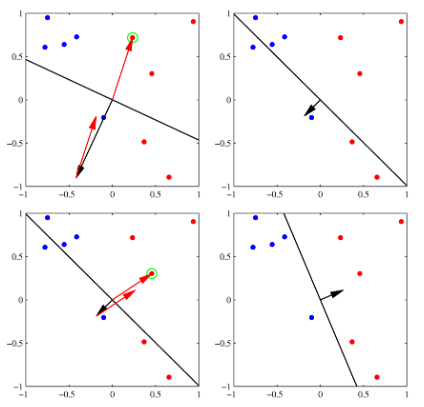
이렇게 root를 찾고 남은 node들은 root부터 시작하여서 x 좌표를 비교해서 이 값이 left 혹은 right인지 확인을 한다. 만약 현재 node에서 이미 left나 right 값이 있다면 그 노드로 이동해서 다시 비교를 하고 지정해주는 작업을 계속해서 반복한다. 따라서 얼마나 많은 반복을 해야할지 모르기 때문에 while을 사용하였으며, 연결을 완료하면 break로 나오도록 하였다.
node 연결을 마친 뒤에 preorder와 postorder는 정의대로 재귀를 사용해서 배열에 담아서 return 하도록 한다. 다만 이 때 많은 node들이 있으면 python의 재귀 메커니즘상 런타임 에러가 발생한다고 한다.
(python은 재귀가 최대 1000회로 제한되어 있다.)
따라서 이를 해결하기 위해서 sys.setrecursionlimit()를 사용해서 최댓값을 넉넉히 늘려주도록 한다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
|
import sys
sys.setrecursionlimit(10**6)
class Tree:
def __init__(self,data,left=None,right=None):
self.data = data
self.left = left
self.right = right
preorderList=[]
postorderList=[]
def preorder(node,nodeinfo):
preorderList.append(nodeinfo.index(node.data)+1)
if node.left:
preorder(node.left,nodeinfo)
if node.right:
preorder(node.right,nodeinfo)
def postorder(node,nodeinfo):
if node.left:
postorder(node.left,nodeinfo)
if node.right:
postorder(node.right,nodeinfo)
postorderList.append(nodeinfo.index(node.data)+1)
def solution(nodeinfo):
answer=[]
sortedNodeinfo=sorted(nodeinfo,key=lambda x : (-x[1],x[0]))
root = None
for node in sortedNodeinfo:
if not root:
root = Tree(node)
else:
current=root
while True:
if node[0] < current.data[0]:
if current.left:
current = current.left
continue
else:
current.left = Tree(node)
break
if node[0] > current.data[0]:
if current.right:
current = current.right
continue
else:
current.right = Tree(node)
break
break
preorder(root,nodeinfo)
postorder(root,nodeinfo)
answer.append(preorderList)
answer.append(postorderList)
return answer
|
cs |
문제링크:
https://programmers.co.kr/learn/courses/30/lessons/42892
코딩테스트 연습 - 길 찾기 게임 | 프로그래머스
[[5,3],[11,5],[13,3],[3,5],[6,1],[1,3],[8,6],[7,2],[2,2]] [[7,4,6,9,1,8,5,2,3],[9,6,5,8,1,4,3,2,7]]
programmers.co.kr
'Algorithm > Python' 카테고리의 다른 글
| [BOJ]13458. 시험 감독 (0) | 2020.03.05 |
|---|---|
| [BOJ]6588. 골드바흐의 추측 (0) | 2020.03.03 |
| [BOJ]13305. 주유소 (0) | 2020.02.25 |
| [BOJ]2485. 가로수 (0) | 2020.02.20 |
| [BOJ]1182. 부분수열의 합 (0) | 2020.02.18 |