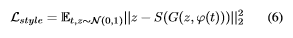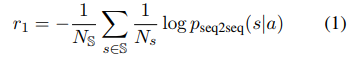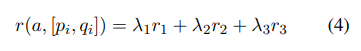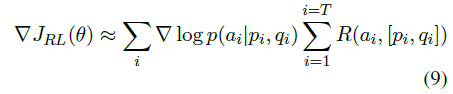어떤 파일 시스템에는 디스크 공간이 파일의 사이즈와 항상 같지는 않다. 이것은 디스크가 일정한 크기의 클러스터로 나누어져 있고, 한 클러스터는 한 파일만 이용할 수 있기 때문이다.
예를 들어, 클러스터의 크기가 512바이트이고, 600바이트 파일을 저장하려고 한다면, 두 개의 클러스터에 저장하게 된다. 두 클러스터는 다른 파일과 공유할 수 없기 때문에, 디스크 사용 공간은 1024바이트가 된다.
파일의 사이즈와 클러스터의 크기가 주어질 때, 사용한 디스크 공간을 출력하는 프로그램을 작성하시오.
입력:
첫째 줄에 파일의 개수 N이 주어진다. N은 1,000보다 작거나 같은 자연수이다. 둘째 줄에는 파일의 크기가 공백을 사이에 두고 하나씩 주어진다. 파일의 크기는 1,000,000,000보다 작거나 같은 음이 아닌 정수이다. 마지막 줄에는 클러스터의 크기가 주어진다. 이 값은 1,048,576보다 작거나 같은 자연수이다.
출력:
첫째 줄에 사용한 디스크 공간을 출력한다.
풀이방법:
파일을 클러스터에 넣으려고 할 떄 크게 3가지 경우가 발생한다.
1. 한 파일의 크기가 한 클러스터의 크기보다 큰 경우
2. 한 파일의 크기가 한 클러스터의 크기와 같은 경우
3.한 파일의 크기가 한 클러스터의 크기보다 작은 경우
그리고 위 3가지 case는 몫과 나머지를 통해서 구할 수 있다.
파일사이즈를 클러스터의 크기로 나눴을 때, 몫이 1보다 커지게 된다면 1의 케이스에 해당하며 몫만큼 클러스터의 개수를 준비하고 나머지가 있을 경우 하나 더 준비하면 된다.
그리고 몫이 0이라면 나머지가 있을 경우에는 한 개를 준비하면 되고, 나머지가 없다면 준비안하면 된다.
강호는 코딩 교육을 하는 스타트업 스타트링크에 지원했다. 오늘은 강호의 면접날이다. 하지만, 늦잠을 잔 강호는 스타트링크가 있는 건물에 늦게 도착하고 말았다.
스타트링크는 총 F층으로 이루어진 고층 건물에 사무실이 있고, 스타트링크가 있는 곳의 위치는 G층이다. 강호가 지금 있는 곳은 S층이고, 이제 엘리베이터를 타고 G층으로 이동하려고 한다.
보통 엘리베이터에는 어떤 층으로 이동할 수 있는 버튼이 있지만, 강호가 탄 엘리베이터는 버튼이 2개밖에 없다. U버튼은 위로 U층을 가는 버튼, D버튼은 아래로 D층을 가는 버튼이다.(만약, U층 위, 또는 D층 아래에 해당하는 층이 없을 때는, 엘리베이터는 움직이지 않는다)
강호가 G층에 도착하려면, 버튼을 적어도 몇 번 눌러야 하는지 구하는 프로그램을 작성하시오. 만약, 엘리베이터를 이용해서 G층에 갈 수 없다면, "use the stairs"를 출력한다.
입력:
첫째 줄에 F, S, G, U, D가 주어진다. (1<=S,G<=F<=1000000, 0<=U,D<=1000000) 건물은 1층부터 시작하고, 가장 높은 층은 F층이다.
출력:
첫째 줄에 강호가 S층에서 G층으로 가기 위해 눌러야 하는 버튼의 수의 최솟값을 출력한다. 만약, 엘리베티어로 이동할 수 없을 때는 "use the stairs"를 출력한다.
풀이방법:
BFS로 경우의 수를 카운팅하면서 최소의 값을 찾을 수 있다. 우선 S와 G가 같으면 버튼을 누를 필요가 없기 때문에 0으로 답을 출력하도록 했다. 이제 이외의 경우에 대해서 BFS를 사용하기 위해, 초기 시작 층인 S로 state를 초기화 했고, 중복방문을 제거하기 위해서 visited를 초기화 했다.
이제 갈 수 없는 경우( 0층, F층 초과)만 있을 때까지 계속 반복하기 위해서 while을 len(state) 초기화 했고, 현재 층을 s라고 할 때 다음과 같은 경우에만 이동하도록 한다.
1. s+U가 F층 이하이고, 방문하지 않은 곳이라면
2. s-F가 1층 이상이고, 방문하지 않은 곳이라면
이를 반복하면서 G가 나타나거나, 1,2 케이스가 하나도 없을 떄까지 반복해서 답을 구하도록 한다.
Text로 실제 이미지와 같은 합성 이미지를 만드는 것은 흥미롭고 유용하지만 많은 연구가 되어 있지는 않다
최근 RNN과 GAN의 연구가 활발해지고 있고 text to image를 이에 적용시켜보도록 한다.
1. Introduction
single-sentence human written descriptions를 image pixel로 바꾸는 것에 관심이 있다.
ex) this small bird has a short, pointy orange beak and white belly -> image
natural language는 물체를 설명하는데 일반적이고 유연한 추론을 제공한다. 따라서 이상적으로 text desciption이 discriminative의 성능을 높힐 것이다.
최근에 text와 image 분야에서 다양한 연구(zero-shot)가 진행되고 있고, 이러한 연구를 바탕으로 char to pixel을 mapping 학습을 시도해본다.
이 문제를 해결하기 위해서는 두 가지 문제를 해결해야 한다.
시각적으로 중요한 것을 잡아내는 text feature 표현을 학습해야 한다.
이 feature를 사용해서 사람이 실제라고 착각할만한 이미지를 만들어내야 한다.
딥러닝은 이 두가지 subproblem을 각각을 잘 해내고 이를 한번에 푸는 것이 목표다.
하지만 딥러닝으로도 어려운 것이 있는데, text 설명을 조건으로 가지는 image의 분포가 매우 높은 multimodal이다
텍스트 설명에 맞는 이미지는 무수히 많기 때문에 쉽지 않다.
image to text에서도 이러한 문제가 발생하지만 문장의 단어를 순차적으로 생성한다.
주어진 이미지와 생성할 단어들을 조합하면 well-defined prediction problem이 된다.
image에서 text를 만드는 것은 한 단어를 기준으로 순차적으로 생성하면 되지만, text에서 image를 만드는 것은 한 번에 진행해야 할 일이기 때문에 어렵다.
새나 꽃 이미지를 text 설명으로 생성하는 것이 목표이며 다음과 같은 dataset을 사용할 것이다.
Caltech-UCSD (Birds)
Oxford-102 (Flowers)
MS COCO (general)
2. Related work
Multimodal learning
어떠한 modal을 사용할지?
여러 modal에서 공유되는 representation 연구
이미지가 여러개 생성된다고 해도 공통되는 특징이 어떠한 것인가
Deep Convolutional decoder network 관련 연구
이미지를 만들어내는 과정이 decoder에 해당하는데 DCN을 기반으로 실제같은 이미지를 합성하는 연구
image to text
이 논문의 반대
3.Background
생략
4.Method
text feature를 조건으로 가지는 DC-GAN을 학습한다. text feature는 hybrid character-level convolutional recurrent neural network로 encoding 했다.
4.1 Network architecture
G : RZ x RT -> RD, D : RD x RT -> {0,1}
T는 text description embedding의 차원
D는 image의 차원
Z는 G의 noise input의 차원
G에서 noise는 정규분포에서, t는 text encoder를 통해 encoding한다. embedding은 fc를 사용해서 작은 차원으로 압축시킨다.(leaky ReLU 사용) 그리고 이를 noise vector z와 합친다. 이 과정을 거친 뒤에 normal deconvolutional network에 진행시켜서 합성된 이미지 x를 얻는다. 이미지 생성은 query text와 noise sample을 바탕으로 진행한다.
D에서, stride가 2인 spatial batch normalization를 수행하고, description embedding의 차원과 같아질때까지 반복한다. 4x4의 차원이 될 때 텍스트 벡터를 복사해서 concat을 다시 수행하고 final score를 구해 분류를 한다.
4.2 Matching-aware discriminator(GAN-CLS)
conditional GAN을 훈련하기 위해 대부분 text와 image 쌍을 joint obeservation 하고, D가 진짜인지 가짜인지 판별하는 방법이다. 하지만 이렇게 naive한 discriminator는 진짜 image가 text embedding context와 일치하는지 알 수 없다.
discriminator가 conditioning information을 무시하고, 쉽게 거절해버리는데 G가 이상하게 생성하기 때문이다. G가 괜찮게 이미지를 생성하기 시작하면 이것이 information을 담고 있는지 판별해야 한다.
일반 naive GAN은 D는 두 개의 input을 가진다. real image with matching text, synthetic image with arbitrary text 그러므로 당연히 두 가지 에러를 가지게 될 것이다. unrealistic image, realistic image but mismatch conditioning information.
따라서 앞서 말한 내용들을 반영하기 위해서 GAN 알고리즘을 수정한다. 세번째 input type을 넣는데, D가 fake라고 반별하는 reacl image with mismatched text이다.
4.3 Learning with manifold interpolation (GAN-INT)
딥러닝은 data manifold 근처에 있는 embedding pari 사이에서 interpolations을 수행해 표현을 학습한다고 밝혀졌다. 이를 이용해서 training set의 embedding으로 부터 interpolation을 수행해 추가적인 text embedding을 얻을 수 있다. 그리고 이 것은 사람이 작성한 text가 아니기 때문에 labeling cost가 발생하지 않는다고 한다. 비슷한 이미지에 대해서 많은 텍스트 임베딩을 만들고 그들이 공유하는 것을 찾아낼 수 있기 때문에 그럴듯한 이미지를 만들 수 있다. 이 것은 다음 목적함수를 보면 알 수 있다.
여기서 z는 noise 분포에서 온 것이고, B는 두 text embeddings를 interpolation한 값이며 보통 0.5로 고정한다.
interpolate 된 embedding은 합성이기 때문에 D는 이 와 연관된 image가 없기 때문에 real을 가지고 있지 않다.그러나 image와 text가 match하는지 예측해야 하기 때문에 fake라고 예측할 것이다. 그러므로 D가 이 것을 잘 수행하면 training points 사이의 data manifold 상에 있는 gap을 메꿀 수 있다.
training points는 유한개이기 때문에 빈 공간이 생길 수 밖에 없는데 무한히 생성한다면 이 공간들을 메꿀 수있을 것이다.
4.4 Inverting the generator for style transfer
text encoding은 image content를 잡아내고, real같은 이미지를 만들기 위해서 noise는 뒷 배경이나 pose같은 style factor를 포착한다. GAN을 훈련시킬 때, query image의 style을 특정한 text 설명의 내용으로 전환시키고 싶다. 이를 하기 위해서 G를 x^에서 z로 거꾸로 흐르게 훈련을 시킨다. 따라서 다음과 같은 squared loss를 가지는 style encode를 가진다.
5. Experiments
Dataset
CUB dataset : 11,788개의 새 이미지
Oxford -102 dataset - 8,189개의 꽃 이미지
Encoder
Text encoder - deep convolutional recurrent text encoder(1024 dimensional)
CUB 데이터로 봤을 때, GAN과 GAN-CLS는 color information 정보는 맞지만 real 같아 보이지는 않다. 하지만 GAN-INT와 GAN-INT-CLS는 이미지가 text를 잘 반영하며 그럴듯한 이미지를 보여주고 있다.
Oxford-102 데이터로 봤을 때에는 4개의 방법 모두 설명을 잘 반영하며 그럴듯한 이미지를 생성하고 있다.
따라서 interpolation을 적용한 방법이 더 좋은 성능을 내는 것이라고 생각된다.
5.2 Disentangling style and content
style과 content를 구분한다. content는 새 자체의 시각적 특징을 의미하며 모양, 크기 각 몸의 색깔을 나타낸다. style은 image의 다른 요소들 뒷 배경이라 새 자체의 pose를 의미한다.
text embedding은 주로 content information을 담당하고, style에는 관여하지 않는다. 그러므로 실제같은 이미지를 생성하기 위해서 GAN은 noise sample z를 잘 학습해야 한다. style encoder에 미지를 줌으로써 style vector를 예측한다. GAN이 image content로 부터 z를 사용해 style을 풀어내고 싶다면 같은 style을 가지는 이미지들 사이의 유사성이 더 높을 것이다.
z를 위해서 이전에 4.4와 같이 구축하고, K-means를 이용해 100개의 cluster를 그룹지었다.
평가를 위해서 4가지 모델에 대해 style encoder를 적용해서 비교해 보았다. cosine 유사도를 사용해 점수를 매겼으며 AU-ROC로 기록했다.?
예상했던 것처럼 caption만을 사용하는 것은 style prediction에 도움을 주지 못했다. 게다가 interpolation을 적용한 것이 더 성능이 좋았다.
5.3 Pose and background style transfer
훈련된 style encoder를 가지고 있는 GAN-INT-CLS는 text 설명이 있는 보지 않은 query image로 부터 style transfer를 수행할 수 있다. style encoder를 이용해 분리해낸 스타일을 다른 이미지를 생성할 때 transfer 할 수 있다.
맨 위의 이미지에서 얻어낸 스타일을 통해서 새로운 이미지를 만들때 이를 사용해서 그럴듯한 이미지를 만드는 것이다. 텍스트만으로 새에 대한 정보를 알 수 없기 때문에 이러한 방법을 사용한다.
5.4 Sentence interpolation
intervening points를 위한 no ground-truth text가 없음에도 불구하고 그럴듯한 이미지를 만들어낼 수 있다.
noise 분포가 같다고 하면 우리가 사용하는 text embedding만 바뀌게 된다. interpolation이 새가 파란색에서 빨간색으로 변하는 것과 같은 color information을 반영할 수 있다. 즉 텍스트의 일부가 변경되어도 noise가 고정되기 때문에 새의 색만 바뀌게 되는 것이다.
반대로 text embedding 값을 interpolate하는 것처럼 두 noise 벡터를 interpolate한 결과로 text 부분이 고정되고 noise와 style이 smooth하게 연결되는 것을 확인할 수 있다.
5.5 Beyond birds and flowers
이제 일반성을 보기 위해서 bird, flower 말고 일반 데이터인 COCO 데이터를 통해서 진행한다. 나름 괜찮은 결과를 얻을 수 있었다. 하지만 중심이 되는 객체가 여러개일 경우에는 잘 반영을 하지 못하고 있으며 추후 연구가 필요하다고 합니다.
6. Conclusions
시각 설명에 기반한 이미지를 생성하는 효과적이고 간단한 모델을 개발했다.
manifold interpolation가 성능을 향상시켰으며, content와 style을 분해하여 복사해내는 모델임을 증명했다.
문제에서 주어진대로 구현을 해도 되지만 stack을 활용해서 풀었다. 각 열별로 newboard에 stack으로 정리를 하며, move를 이용해서 각 열에 있는 값들을 pop을 해서 빼온다. move에 해당하는 열에 값이 없다면 continue로 행동을 넘기며 값이 있다면 basket에 값을 넣는다.
basket에 값을 넣었다면 위의 두 값이 같은지 확인하고 같다면 pop을 사용해서 빼고 answer 카운트를 2 증가시킨다. (두 값이 같아 없어지는 행위를 세는 것이 아니라 없어진 것의 개수를 구하는 것이므로 2를 더하는게 맞다.)
Deep Reinforcement Learning for Dialogue Generation
Abstract
Dialogue Generation을 RNN으로 하는 것이 좋은 가능성을 보인기는 했지만, 근시안적으로 바라보며 미래에 다가올 영향을 생각하지 않고 대화를 생성하는 경향이 있다.
이러한 문제점이 발생했기 때문에 NLP 모델에 RL을 넣으려는 시도를 해보려고 한다.
이 모델은 두 개의 가상 agent로부터 대화를 생성한다.
policy gradient 방법을 사용한다.
대화의 품질을 높힐 수 있는 세 가지 reward를 도입했다.
informativity
coherence
ease of answering
우리는 이 모델을 diversity와 length를 지표로 평가를 할 것이다.
1. Introduction
Neural response generation에 대해서 많은 연구가 이루어졌다.
Seq2Seq 모델이 Dialogue Generation에서 성공을 이뤘음에도 불구하고 두 가지 문제점이 있다.
SEQ2SEQ 모델은 MLE를 사용해서 주어진 대화 문맥을 통해서 다음 단어를 예측한다.
그러나 MLE는 실생활에 chatbot을 도입하기에는 적합하지 않다.
사람에 의해 학습이 되는 것인데, 다양성을 보장하기 어렵다.
가장 대표적인 예시로 "I don't know"와 같이 input과 상관없이 사용할 수 있는 답변을 가장 많이 하게 된다.
이러한 것들이 다양성을 낮추게 되는 것이다.
위 테이블의 왼쪽 예시처럼 같은 말이 반복되는 무한 루프에 빠지게 될 가능성이 높다.
이것도 역시 MLE-based SEQ2SEQ 모델로 인해 발생하게 되는 문제이다.
이러한 문제를 해결하기 위해서 다음 두 가지를 도전 과제로 잡았다.
chatbot 개발을 잘하기 위해서 개발자가 직접 정의한 reward를 도입한다.
대화가 진행되면서 long-term influence를 해결하도록 한다.
이러한 목표를 달성하기 위해서 이번 논문에서는 MDP나 POMDP dialogue system의 개념을 사용하도록 한다.
이 방법을 사용하면 long-term reward를 최적화할 수 있을 것이다.
우리 모델은 encoder-decoder 구조를 기본으로 가지고 있으며, reward를 최대화 하는 방향으로 2개의 가상 에이전트가 대화를 시뮬레이션으로 하는 방법을 사용한다.
좋은 대화를 만들기 위해서 reward에 관해 간단한 heuritic한 가정을 정의했다.
좋은 대화란 forward-looking하고 interactive, informative, coherent라고 한다.
encoder-decoder RNN은 policy로 정의되며, long-term developer-defined reward를 최적화하기 위해서 policy gradient 방법을 사용해 학습한다고 한다.
SEQ2SEQ에 RL의 강점을 부여한 모델이라고 생각하면 되고, 일반적인 SEQ2SEQ와 비교해본다.
2. Related Work
생략
3. Reinforcement Learning for Open-Domain Dialogue
learning system은 2개의 agent로 구성되어 있으며, p를 첫 agent가 생성한 문장, q를 두번째 agent가 생성한 문장으로 정의한다.
2개의 agent는 서로 교대로 대화를 하며 진행을 한다.
즉 p1,q1,p2,q2,...,pi,qi와 같이 진행한다.
action은 대화를 생성하는 것으로 정의를 한다.
policy는 encoder-decoder RNN을 사용한다.
파라미터는 뒤에서 이야기 하도록 한다.
Policy gradient 방법이 Q-learning보다 더 적합하다고 생각한다.
Q-learning은 각 행동에 대해서 바로 미래 가치 reward를 추정하는데, 이는 long-term reward를 최대화 하려고 하는 목적과 다르기 때문이다?
3.1 Action
action a는 문장을 생성하는 것으로, action space는 생성하려는 문장이 가변적이고 의미적으로도 다양하므로 무한하다.
3.2 State
state는 이전 두 dialogue [pi,qi]로 정의되며 이를 encoding해서 vector representation으로 input으로 넣어주게 된다.
3.3 Policy
LSTM Encoder-decoder의 형태를 가져온다. 그리고 stochastic representation of the policy를 사용한다.
3.4 Reward
r은 each action에서 얻어지는 것이며, 대화의 성공을 위해 중요한 요소이다. 이러한 요소들을 어떻게 추정할 것인지에 대해 이야기 한다.
Ease of answering
기계가 대답하는 것이 쉽게 하는 것이다. 이는 앞서 말한 forward-looking function과 연관있다.
이 것을 dull response의 대답에 대한 negative log likelihood를 사용해서 측정한다.
SEQ2SEQ에서 발생했던 dull response S list를 사용한다.
reward function은 다음과 같이 생겼다.
NS는 dull response의 수이다.
Information Flow
각 agent가 대화가 진행되고, 반복을 피하면서 새로운 말을 하는 것을 원한다.
따라서 같은 agent로 부터의 연이은 대화 사이의 의미론적 유사도를 사용한다.
hpi, hpi+1를 encoder로 부터 얻을 수 있으며, reward는 negative log of the cosine similarity를 사용해서 구한다.
Semantic Coherence
문법적으로 틀리거나 일관성이 없는 문장을 제외하고는 높은 보상을 주도록 해야 한다.
생성된 응답이 일관성이 있고 적절함을 보장하기 위해서 action a와 previous turn 사이의 mutual information을 고려하도록 한다.
첫번째 term은 probability of generating response a given the previous dialogue utterance이다
두번째 term은 backward probability of generating the previous dialogue utterance qi based on response a 이다.
Final
최종적으로는 다음과 같이 reward를 계산한다.
λ1+λ2+λ3=1을 만족해야 하며, 이번 모델에서는 λ1=0.25, λ2=0.25, λ3=0.5로 설정했다.
4. Simulation
main idea는 두 개의 가상 agent가 서로 대화를 하면서 state-action space를 탐색하고, policy를 배워 optimal expected reward를 이끌어내는 것이다.
4.1 Supervised Learning
training을 하기 위해 supervised SEQ2SEQ model을 사용해서 주어진 dialogue history로 target sequence를 생성하는 예측 사전작업을 한다.
attention을 가진 SEQ2SEQ을 학습한다.
dataset에 있는 each turn을 target으로 간주한다.
두 이전의 sentence의 결합은 source input으로 간주한다.
4.2 Mutual Information
SEQ2SEQ의 sample은 dull 하고 generic하다.(ex)"i don't know")
pre-trained된 SEQ2SEQ 모델로 policy model을 초기화하는 것을 원하지 않는다.
왜냐하면 이 것은 RL 모델의 경험에서 다양성의 부족을 이끌어내기 때문이다.
Li et al(2016a)에서 source와 target의 mutual information이 dull한 대답을 확실하게 줄이고, 일반적인 대답의 품질을 향상시켰다.
따라서 mutual information response를 최대화하는 encoder-decoder 모델을 사용하였다.
이 논문에서 소개된 것은 실현 불가능하다. 왜냐하면 Eq3에서 second term은 완전하게 생성된 target sentence가 필요하기 때문이다.
sequence level learning에 관한 최근 연구에 영감을 받아 maximum mutual information response를 생성하는 문제를 mutual information value의 reward가 model이 sequence의 끝에 도달하는 RL 문제로 취급한다.
Ranzato와 유사하게 최적화를 위해서 policy gradient 방법을 사용한다. 우리는 pre-trained model을 사용해서 policy model을 초기화하고, input source를 넣어서 candidate list를 생성한다.
생성된 값들을 mutual information score을 가지게 된다.
이 mutual information score은 reward로 사용이 되고, encoder-decoder의 back-propagated로 사용된다.
expected reward는 다음과 같이 주어진다.
likelihood ratio를 사용해 추정한 gradient는 다음과 같다.
stochastic gradient descent를 사용해서 encoder-decoder 속의 parameter를 업데이트 한다.
curriculum learning 전략을 사용해서 모든 T 길이의 sequence 중 첫 L개 token은 MLE loss를 사용하고, reinforcement 알고리즘으로 T-L개 token을 사용한다. 점차적으로 L을 0으로 줄이도록 한다.
baseline 전략은 variance를 줄이기 위한 방법이다.
4.3 Dialogue Simulation between Two Agent
2개의 가상 agent 사이에서 대화를 simulation 하는 방식으로 진행한다.
training set에서 뽑은 message를 1번 agent에게 준다.
agent는 input message를 vector representation으로 encoding 한 후, response output을 생성하기 위해 decoding 한다.
생성된 output을 dialogue history에 넣고 다음 agent가 2번을 수행한다.
Optimization
mutual information model의 parameter로 pRL을 초기화 한다.
더 큰 expected reward를 얻기 위해 policy gradient를 사용한다. objective 함수는 다음과 같다.
likelihood ratio trick을 사용해 gradient는 다음과 같이 구한다.
4.4 Curriculum Learning
dialogue의 2 turn을 simulating 하는 것으로 부터 시작해서 5개까지 늘리는 것을 목표로 한다.
5. Experimental Results
human judgments와 two automatic metric를 사용해서 비교한다.
conversation length
diversity
5.1 Dataset
dialogue simulation은 high-quality initial input이 필요하다.
만약 첫 시작부터 "why?", "i don't know what you are taking about"와 같은 것이 들어오게 된다면 훈련이 잘 안될 것이다.
5.2 Automatic Evaluation
true response quality보다는 long-term success of the dialogue이 목표이기 때문에 BLEU나 perplexity를 평가지표로 활용하지 않는다.
Length of the dialogue
이 논문에서 제안하는 first metric은 simulated dialogue의 length이다.
"i don't know"와 같은 dull response를 생성하거나 같은 agent로 부터의 응답이 같을 경우 end라고 한다.
test set은 1,000개의 input message로 구성되어 있다.
circular dialogue의 위험을 줄이기 위해서 turn을 8개로 제한했다.
결과는 다음 표와 같다.
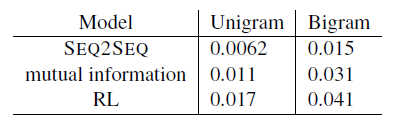
mutual information이 SEQ2SEQ보다 더 긴 대화를 나누었고, mutual information으로 훈련을 하고 RL의 장점을 추가한 RL 모델이 가장 좋은 결과를 얻었다.
Diversity
generated response에서 distinct unigram과 bigram의 수를 계산하는 것으로 diversity를 본다.
value를 favoring long sentence를 피하기 위해서 생성된 toal number로 scaled 했다. (by Li et al. (2016a).)
SEQ2SEQ 모델과 RL 모두 beam size를 10으로 해서 beam search를 수행했다.
mutual information model은 pSEQ2SEQ(t|s)를 사용해서 n-best list를 생성하고 pSEQ2SEQ(s|t)를 사용해서 linearly re-rank했다.
RL 모델이 diversity가 가장 높다는 것을 알 수 있다.
Human Evaluation
human evaluation에 three setting이 있음.
crowdsourced judge to evaluate a random sample of 500 items (by Li et al (2016a))
single-turn general quality에 해당
input message 와 generated output을 3단계로 나타냄.
어떤 output이 better인지 물어본다. (Tie도 허용)
동일한 string은 같은 점수를 부여한다.
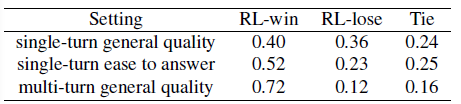
RL 모델로 mutual information보다 좋은 점수를 받음
judge는 다시 input message와 system outpus으로 표현한다.
single-turn ease to answer에 해당
그리고 어떤 output이 respond하기 easy한지 물어본다.
500 items을 다시 3 judge로 평가한다.
두 agent 사이에 simulated conversation으로 표현한다.
multi-turn general quality에 해당
각 대화는 5개의 turn으로 구성되고 200개의 시뮬레이션된 대화가 있다.
이 역시 3 judge로 수행한다.
사람들이 평가한 표를 위와 같다.
대답을 잘 했는지에 대한 비교는 40퍼 승, 36퍼 패로 비슷하다.
하지만 얼마나 장기적으로 대화를 했는가 문제에서는 RL이 훨씬 좋은 성능을 보였다.
Qualitative Analysis and Discussion
random sample에 대해 응답한 mutual information model과 RL 모델의 비교이다.
RL 모델로 생성한 것이 더 interactive한 응답을 했다.
그리고 RL 모델이 대답을 다른 질문을 하는 것으로 sentence를 끝내는 경향이 보인다.
error analysis를 할 때 발견된 것으로 반복되는 응답에 패널티를 부여했지만 다음과 같이 긴 cycle이 존재하는 반복이 존재한다.
우리가 생각할 수 있는 대화의 양이 제한되어 있기 때문인 것 같다?
다른 문제로는 모델이 가끔 관계 없는 주제를 이야기 하는 경우도 있다.
중요한 문제는 당연하게도 우리가 임의로 정해준 reward로 이상적인 대화를 만들기 위해서 모든 면을 cover할 수는 없다.
현재 모델의 다른 문제점은 적은 수의 candidate를 고려할 수 밖에 없다는 것이다.
6. Conclusion
RL 과 SEQ2SEQ의 각각 강점을 dialogue에 적용해보았다.
이전의 SEQ2SEQ와 같이 dialogue turn의 의미와 적절한 응답을 할 수 있었다.
RL의 특성으로 봤을 때, 미래 지향적인 점을 충분히 잡았다.
우리의 모델이 간단하다는 사실에도 불구하고, global 특성을 잡았고, 더 다양하고 interactive한 응답을 보여주었다.
Vigenere cipher이라는 암호화 방법은 암호화하려는 문장(평문)의 단어와 암호화 키를 숫자로 바꾼 다음, 평문의 단어에 해당하는 숫자에 암호 키에 해당하는 숫자를 더하는 방식이다. 이 방법을 변형하여 평문의 단어에 암호화 키에 해당하는 숫자를 빼서 암호화하는 방식을 생각해 보자.
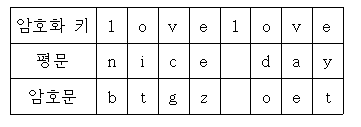
예를 들어 암호화 키가 love이고, 암호화할 문장이 "nice day"라면 다음과 같이 암호화가 이루어진다.
제시된 평문의 첫 번째 문자인 'n'은 해당 암호화 키 'l'의 알파벳 순서가 12이므로 알파벳상의 순서에서 'n'보다 12앞의 문자인 'b'로 변형된다.
변형된 문자가 'a'이전의 문자가 되면 알파벳 상에서 맨 뒤로 순서를 돌린다. 예를 들면 평문의 세 번째 문자인 'c'는 알파벳 상에서 3번째이고 대응하는 암호화키 'V'는 알파벳 순서 22로 'c'에서 22 앞으로 당기면 'a'보다 훨씬 앞의 문자이어야 하는데, 'a' 앞의 문자가 없으므로 'z'로 돌아가 반복되어 'g'가 된다. 즉 평문의 문자를 암호화키의 문자가 알파벳 상에서 차지하는 순서만큼 앞으로 뺀 것으로 암호화한다.
평문의 문자가 공백 문자인 경우는 그 공백 문자를 그대로 출력한다.
이과 같은 암호화를 행하는 프로그램을 작성하시오.
입력:
첫째 줄에 평문이, 둘째 줄에 암호화 키가 주어진다.
평문은 알파벳 소문자와 공백문자(space)로만 구성되며, 암호화 키는 알파벳 소문자만으로 구성된다. 평문의 길이는 공백까지 포함해서 30000자 이하이다.
출력:
첫 번째 줄에 암호문을 출력한다.
풀이방법:
암호화 키와 평문의 차이를 알아야 하므로 ascii코드 값으로 바꿔 주는 ord 함수를 사용한다. 이를 이용해서 암호화 키와 평문의 차이를 구하고 이 값이 0보다 큰지 작은지를 결정한다.
0보다 크다면 해당 차이 값이 96을 더해주도록 한다.(소문자 'a'의 ascii는 97이다.)
김형택은 탑문고의 직원이다. 김형택은 계산대에서 계산을 하는 직원이다. 김형택은 그날 근무가 끝난 후에, 오늘 판매한 책의 제목을 보면서 가장 많이 팔린 책의 제목을 칠판에 써놓는 일도 같이 하고 있다.
오늘 하루 동안 팔린 책의 제목이 입력으로 들어왔을 때, 가장 많이 팔린 책의 제목을 출력하는 프로그램을 작성하시오.
입력:
첫째 줄에 오늘 하루 동안 팔린 책의 개수 N이 주어진다. 이 값은 1,000보다 작거나 같은 자연수이다. 둘째부터 N개의 줄에 책의 제목이 입력으로 들어온다. 책의 제목의 길이는 50보다 작거나 같고, 알파벳 소문자로만 이루어져 있다.
출력:
첫째 줄에 가장 많이 팔린 책의 제목을 출력한다. 만약 가장 많이 팔린 책이 여러 개일 경우에는 사전 순으로 가장 앞서는 제목을 출력한다.
풀이방법:
hash를 사용해서 책의 제목을 효과적으로 세도록한다. python에서는 dict 자료형을 사용해서 구현하면 된다.
책의 이름을 key로 하고 책의 개수를 value로 설정한다. 따라서 get을 사용해서 dict에(전체 책 리스트) 해당 key(책의 이름)가 있는지 확인하고 있다면 key에 해당하는 value(책의 개수)를 하나 올려주고, 없다면 해당 key를 dict에 value가 1인 상태로 넣어준다.
이렇게 책을 hash 상태로 정리했다면 items()를 통해서 key,value 쌍으로 가져오고, sort 조건에 맞게 정렬해서 값을 구하도록 한다.