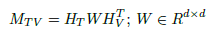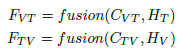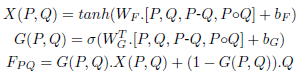728x90
반응형
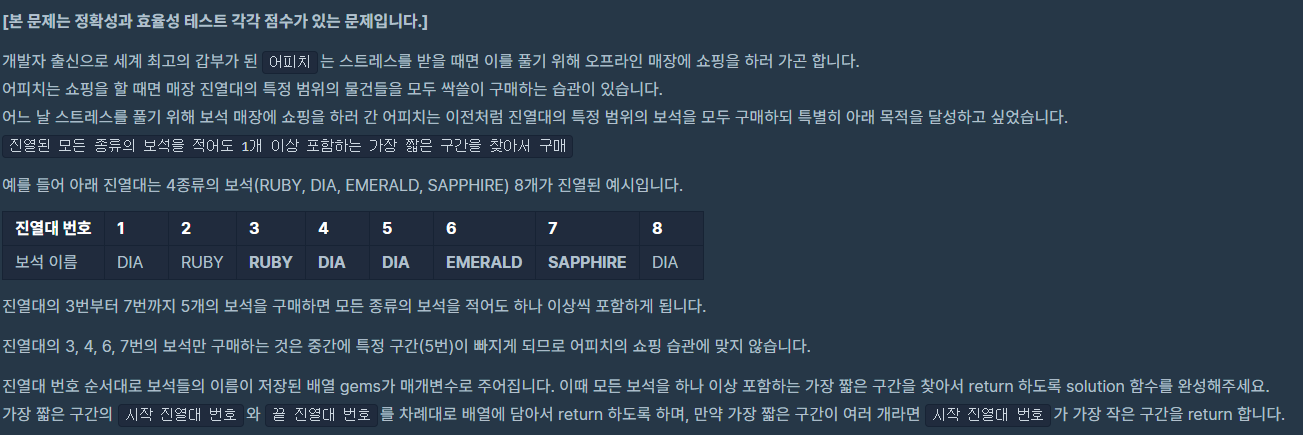
문제:
풀이방법:
효율적으로 풀어야 하는 문제이기 때문에 O(N^2) 방법으로는 시간초과에 걸릴 것이다. 따라서 투 포인터를 사용하는 슬라이딩 윈도우를 사용해서 풀었다.
우선 앞에서부터 뒷 포인터를 이동시키면서 모든 보석을 포함할 때까지 이동한다. 모든 보석을 포함하게 된다면 앞 포인터를 움직여서 가장 앞에 존재했던 보석을 뺀다. 그래도 모든 보석이 포함되어 있다면 앞 포인터를 움직여서 다시 앞을 빼고, 모든 보석이 포함되어 있지 않다면 뒷 포인터를 움직여서 다시 모든 보석을 포함시킬 때까지 움직인다.
이 과정을 반복하면서 가장 짧은 길이의 포인터들을 저장해두고 최종적으로 출력하도록 한다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
|
def solution(gems):
answer = []
initGems = len(set(gems))
gemCount = {}
gemSet = set()
start,answerStart = 0, 0
last,answerLast = 0, 0
diff = 999999999
swLast = -1
for s in range(len(gems)):
findsw = False
for l in range(swLast+1,len(gems)):
if len(gemSet) == initGems:
findsw = True
if abs(l-s-1) < diff:
diff = abs(l-s-1)
answerStart = s
answerLast = l-1
swLast = l-1
break
if not gemCount.get(gems[l]):
gemCount[gems[l]] = 1
gemSet.add(gems[l])
else:
gemCount[gems[l]] +=1
if not findsw:
if len(gemSet) == initGems:
findsw = True
if abs(l-s) < diff:
diff = abs(l-s)
answerStart = s
answerLast = l
swLast = l
break
if gemCount.get(gems[s]):
if gemCount[gems[s]]==1:
del gemCount[gems[s]]
gemSet.remove(gems[s])
else:
gemCount[gems[s]] -=1
answer.append([answerStart+1,answerLast+1])
return answer[0]
|
cs |
문제링크:
https://programmers.co.kr/learn/courses/30/lessons/67258
코딩테스트 연습 - 보석 쇼핑
["DIA", "RUBY", "RUBY", "DIA", "DIA", "EMERALD", "SAPPHIRE", "DIA"] [3, 7]
programmers.co.kr
728x90
반응형
'Algorithm > Python' 카테고리의 다른 글
| [BOJ]18258. 큐2 (0) | 2020.07.23 |
|---|---|
| [BOJ]4963. 섬의 개수 (0) | 2020.07.21 |
| [BOJ]2164. 카드2 (0) | 2020.07.14 |
| [Programmers]2020 카카오 인턴십. 수식 최대화 (0) | 2020.07.09 |
| [Programmers]2020 카카오 인턴십. 키패드 누르기 (0) | 2020.07.07 |