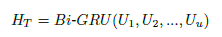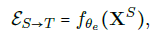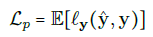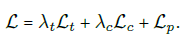도영이는 짜파구리 요리사로 명성을 날렸었다. 이번에는 이전에 없었던 새로운 요리에 도전을 해보려고 한다.
지금 도영이의 앞에는 재료가 N개 있다. 도영이의 각 재료의 신맛 S와 쓴맛 B를 알고 있다. 여러 재료를 이용해서 요리할 때, 그 음식의 신맛은 사용한 재료의 신맛의 곱이고, 쓴맛은 합이다.
시거나 쓴 음식을 좋아하는 사람은 많지 않다. 도영이의 재료를 적절히 섞어서 요리의 신맛과 쓴맛의 차이를 작게 만들려고 한다. 또, 물을 요리라고 할 수는 없기 때문에, 재료는 적어도 하나 사용해야 한다.
재료의 신맛과 쓴맛이 주어졌을 때, 신맛과 쓴맛의 차이가 가장 작은 요리를 만드는 프로그램을 작성하시오.
입력:
첫째 줄에 재료의 개수 N(1<=N<=10)이 주어진다. 다음 N개 줄에는 그 재료의 신맛과 쓴맛이 공백으로 구분되어 주어진다. 모든 재료를 사용해서 요리를 만들었을 때, 그 요리의 신맛과 쓴맛은 모두 1,000,000,000보다 작은 양의 정수이다.
출력:
첫째 줄에 신맛과 쓴맛의 차이가 가장 작은 요리의 차이를 출력한다.
풀이방법:
각 재료에 따라서 넣고 빼고 하는 작업을 재귀로 구현을 했다. mix라는 함수를 재귀적으로 호출하고, sour와 bitter의 배열의 크기를 줄여나가면서 재귀를 진행한다. 이 배열의 길이가 0이 될 때까지 반복하며, 결과값을 global 변수인 answer에 모두 담고, min 값을 출력한다.
KOI 통신연구소는 레이저를 이용한 새로운 비밀 통신 시스템 개발을 위한 실험을 하고 있다. 실험을 위하여 일직선 위에 N개의 높이가 서로 다른 탑을 수평 직선의 왼쪽부터 오른쪽 방향으로 차례로 세우고, 각 탑의 꼭대기에 레이저 송신기를 설치하였다. 모든 탑의 레이저 송신기는 레이저 신호를 지표면과 평행하게 수평 직선의 왼쪽 방향으로 발사하고, 탑의 기둥 모두에는 레이저 신호를 수신하는 장치가 설치되어 있다. 하나의 탑에서 발사된 레이저 신호는 가장 먼저 만나는 단 하나의 탑에서만 수신이 가능하다.
예를 들어 높이가 6, 9, 5, 7, 4인 다섯 개의 탑이 수평 직선에 일렬로 서 있고, 모든 탑에서는 주어진 탑 순서의 반대 방향(왼쪽 방향)으로 동시에 레이저 신호를 발사한다고 하자. 그러면 높이가 4인 다섯 번째 탑에서 발사한 레이저 신호를 높이가 7인 네 번째 탑이 수신을 하고, 높이가 7인 네 번째 탑의 신호는 높이가 9인 두 번째 탑이, 높이가 5인 세 번째 탑의 신호도 높이가 9인 두 번째 탑이 수신을 한다. 높이가 9인 두 번째 탑과 높이가 6인 첫 번째 탑이 보낸 레이저 신호는 어떤 탑에서도 수신을 하지 못한다.
탑들의 개수 N과 탑들의 높이가 주어질 때, 각각의 탑에서 발사한 레이저 신호를 어느 탑에서 수신하는지를 알아내는 프로그램을 작성하라.
입력:
첫째 줄에 탑의 수를 나타내는 정수 N이 주어진다. N은 1이상 500,000 이하이다. 둘째 줄에는 N개의 탑들의 높이가 직선상에 놓인 순서대로 하나의 빈칸을 사이에 두고 주어진다. 탑들의 높이는 1 이상 100,000,000 이하의 정수이다.
출력:
첫째 줄에 주어진 탑들의 순서대로 각각의 탑들에서 발사한 레이저 신호를 탑들의 번호를 하나의 빈칸을 사이에 두고 출력한다. 만약 레이저 신호를 수신하는 탑이 존재하지 않으면 0을 출력한다.
풀이방법:
N이 최대 500,000개 이기 때문에 효율적으로 알고리즘을 구성해야 하고, 따라서 스택 자료 구조를 사용하게 되었다.
알고리즘은 다음과 같은 과정을 반복한다.
1. 현재 인덱스에 존재하는 탑의 높이와 스택의 끝(가장 마지막에 넣은 값)과 비교한다.
1-1. 만약 스택이 비어 있다면 0을 넣고, 현재 인덱스 값을 (위치, 값) 형식으로 스택에 넣는다.
2. 만약 현재 인덱스 탑 높이가 더 크다면, 스택의 마지막 값이 현재 인덱스의 탑 높이가 커지거나 비워질 때까지 계속 pop한다.
3. 스택의 마지막 값이 현재 인덱스의 탑 높이보다 크다면, 스택의 마지막 값의 위치 값을 answer에 넣고, 스택에 현재 인덱스 값을 (위치, 값) 형식으로 넣는다.
수현이는 4차 산업혁명 시대에 살고 있는 중학생이다. 코로나 19로 인해, 수현이는 버추얼 학교로 버추얼 출석해 버추얼 강의를 듣고 있다. 수현이의 버추얼 선생님은 문자가 2개인 연립방정식을 해결하는 방법에 대해 강의하고, 다음과 같은 문제를 숙제로 냈다.
다음 연립 방정식에서 x와 y의 값을 계산하시오.
4차 산업혁명 시대에 숙제나 하고 앉아있는 것보다 버추얼 친구들을 만나러 가는 게 더 가치있는 일이라고 생각했던 수현이는 이런 연립방정식을 풀 시간이 없었다. 다행히도, 버추얼 강의의 숙제 제출은 인터넷 창의 빈 칸에 수들을 입력하는 식이다. 각 칸에는 -999 이상 999 이하의 정수만 입력할 수 있다. 수현이가 버추얼 친구들을 만나러 버추얼 세계로 떠날 수 있게 도와주자.
입력:
정수 a,b,c,d,e,f가 공백으로 구분되어 차례대로 주어진다. (-999<=a,b,c,d,e,f<=999)
문제에서 언급한 방정식을 만족하는 (x,y)가 유일하게 존재하고, 이 때 x와 y사 각각 -999 이상 999 이하의 정수인 경우만 입력으로 주어짐이 보장된다.
출력:
문제의 답인 x와 y를 공백으로 구분해 출력한다.
풀이방법:
연립방정식을 푸는 방법은 보통 가감법을 많이 사용한다. 따라서 가감법을 사용해서 x와 y에 대한 식을 계산하면 다음과 같이 정리되고, 해당하는 값을 넣어주면 값이 나올 것이다. 답은 항상 정수이기 때문에 // 를 사용했다.
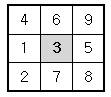
스도쿠는 18세기 스위스 수학자가 만든 '라틴 사각형'이랑 퍼즐에서 유래한 것으로 현재 많은 인기를 누리고 있다. 이 게임은 아래 그림과 같이 가로, 세로 각각 9개씩 총 81개의 작은 칸으로 이루어진 정사각형 판 위에서 이뤄지는데, 게임 시작 전 몇 몇 칸에는 1부터 9까지의 숫자 중 하나가 쓰여 있다.
나머지 빈 칸을 채우는 방식은 다음과 같다.
1. 각각의 가로줄과 세로줄에는 1부터 9까지의 숫자가 한 번씩만 나타나야 한다.
2. 굵은 선으로 구분되어 있는 3x3 정사각형 안에도 1부터 9까지의 숫자가 한 번씩만 나타나야 한다.
위의 예의 경우, 첫재 줄에는 1을 제외한 나머지 2부터 9까지의 숫자들이 이미 나타나 있으므로 첫째 줄 빈칸에는 1이 들어가야 한다.
또한 위쪽 가운데 위치한 3x3 정사각형의 경우에는 3을 제외한 나머지 숫자들이 이미 쓰여있으므로 가운데 빈칸에는 3이 들어가야 한다.
이와 같이 빈 칸을 차례로 채워 가면 다음과 같은 최종 결과를 얻을 수 있다.
게임 시작 전 스도쿠 판에 쓰여 있는 숫자들의 정보가 주어질 때 모든 빈 칸이 채워진 최종 모습을 출력하는 프로그램을 작성하시오.
입력:
아홉 줄에 걸쳐 한 줄에 9개씩 게임 시작 전 스도쿠판 각 줄에 쓰여 있는 숫자가 한 칸씩 띄워서 차례로 주어진다. 스도쿠 판의 빈 칸의 경우에는 0이 주어진다. 스도쿠 판을 규칙대로 채울 수 없는 경우의 입력은 주어지지 않는다.
출력:
모든 빈 칸이 채워진 스도쿠 판의 최종 모습을 아홉줄에 걸쳐 한 줄에 9개씩 한 칸씩 띄워서 출력한다.
스도쿠 판을 채우는 방법이 여럿인 경우는 그 중 하나만을 출력한다.
풀이방법:
pypy3로 통과한 코드입니다. 0인 점에서 가능한 모든 경우의 수를 탐색하면서 백트래킹을 수행해 python3에서 통과하지 못한듯 합니다.
우선 sudoku 배열에 입력을 모두 받아준 뒤에 이를 순회하면서 0인 점을 찾아서 toDoList로 만들어 준다.
이를 인덱스로 접근하는 재귀 함수 check에 넣어주면서 백트래킹을 수행한다.
isPromising를 통해서 가능한 경우의 수를 구해주도록 했다. set 자료형과 차집합을 이용해서 경우의 수를 구하도록 했다. 이 경우의 수를 넣어보면서 dfs 방식으로 답을 구해주도록 한다.
인덱스가 끝까지 진행을 하면 sys.exit()로 바로 종료하도록 했다. (스도쿠 판을 규칙대로 채울 수 없는 경우의 입력은 주어지지 않으며, 여럿인 경우여도 하나만 출력하면 되기 때문이다.)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
import sys
sudoku = [list(map(int,sys.stdin.readline().split())) for _ inrange(9)]
toDoList = []
for i inrange(9):
for j inrange(9):
if sudoku[i][j] ==0:
toDoList.append((i,j))
def isPromising(i,j):
numbers = set(range(1,10))
numbers -= set(sudoku[i])
numbers -= set([sudoku[t][j] for t inrange(9)])
numbers -= set([sudoku[p][q] for p inrange(3*(i//3),3*(i//3+1))
이 사진은 오래전부터 인터넷에 돌아다니는 사진으로, 작년 전대프연 예선 A번에서는 수학을 정말 못 하는 고등학생인 성원이의 시험지로 소개되었다. 저작권이 있는 사진일 수 있어 알아보기 어렵게 가공했음을 양해 바란다.
예선 날짜가 다가오는데도 적당한 A번 문제를 생각하지 못한 출제진은 작년 전대프연 예선 A번을 응용해서 문제를 만들기로 했다. 이를 위해 사진 속 문제를 찾아본 출제진은 해당 문제가 2007학년도 6월 고등학교 1학년 전국연합학력평가 수리 영역 26번임을 알게 되었다.
시험지를 내려받고 문제들을 살펴보던 출제진은 아래와 같은 문제를 발견했다.
예상했겠지만, 여러분은 이제 위의 19번 문제 세 번째 줄에 등장하는 수 '1000'을 임의의 자연수로 바꾸었을 때 그에 해당하는 답을 출력하는 프로그램을 작성해야 한다.
입력:
첫 번째 줄에 자연수 n (1<=n<=10^9)이 주어진다.
출력:
첫 번째 줄에 19번 문제 세 번째 줄에 등장하는 수 '1000'을 자연수 n으로 바꾸었을 때 그에 해당하는 답의 번호를 출력한다. 즉, 1 이상 5 이하의 자연수 중 하나를 출력해야 한다.
풀이방법:
구현을 하는 문제다.
1~5는 숫자 그대로 답이 되는 경우이기 때문에 따로 처리를 했고, 이를 제외해야지 4의 배수로 나머지 경우를 처리를 하기 쉽기 때문에 따로 처리했다.
6 이상부터는 4의 배수를 기준으로 왼쪽으로 진행, 오른쪽으로 진행하는 층이 바뀌게 된다. (ex 8은 왼쪽 진행, 12는 오른쪽 진행) 4의 배수중 짝수가 왼쪽으로 진행이고, 홀수가 오른쪽 진행이다. 이를 위해서 n을 4로 나눴을 때, 나머지가 2 이상이면 몫을 하나 늘리고, 그 외는 몫을 그대로 사용해서 현재 층을 파악하도록 했다.
Gated Mechanism For Attention Based Multimodal Sentiment Analysis
Abstract
Multimodal Sentiment Analysis(이하 msa)는 최근 인기를 얻고 있는데 그 이유는 social media가 발전하고 있기 때문이다.
이 논문에서는 msa의 세 가지 면을 소개한다.
얼마나 많은 modality가 sentiment에 기여하는지
장기 의존성을 해결할 수 있는지
unimodal의 fusion과 cross modal cue
이 세가지 면에서 cross modal interaction을 배우는 것이 이 문제를 해결하는데 효과적인 것을 알 수 있었다.
CMU-MOSI나 CMU-MOSEI 데이터셋에서 좋은 성능을 보였다.
1. Introduction
Facebook, Whatsapp, Instagram and YouTube와 같은 소셜 미디어들이 발전하면서 sentiment analysis가 중요해졌다. msa는 acoustic, visual, textual를 같이 사용한다.
msa를 하는 방법에는 다음 세 가지 타입이 있다.
modality를 각각 학습하고 output을 fuse 하는 방법
여러 개의 modality를 jointly 학습하는 방법
attention based technique을 사용해서 각 unimodal들이 얼마나 기여하는지 알아보는 방법
그래서 더 나은 cross modal information을 배우기 위해서 cross interaction 동안 정보를 조절하는 conditional gating mechanism을 제안한다.
게다가 video에서 장기 의존성을 잡기 위해서 각 unimodal contextual representation에 self-attention layer를 적용한다. self-attention을 사용하는 장점은 direct interaction을 가능하게 하고, network에서 제한없는 information flow를 제공한다.
논문에서 제안하는 방법에서 중요한 것은 다음과 같다.
cross interaction간에 정보를 조절할 수 있는 gating mechanism을 배운다.
self-attend가 장기 의존성을 잡을 수 있다.
self 및 gated 기반의 recurrent layer는 더 정확한 multimodal을 얻을 수 있다.
2. Proposed Approach
학습가능한 gate에 의해 조절되는 서로 다른 modality사이에 interaction을 배우는 것이 목적이다. 전체적인 구조는 아래와 같다.
2.1 Contextual Utterance Representation
Bi-GRU를 통해서 각 modality에서 specific contextual representation을 얻는다. 다음은 text를 뜻하는 representation이다.
2.2 Self Attention
장기 의존성을 잡기 위해서 bilinear attention을 사용한다. 100개의 utterance가 있어도 self-attention은 장기 context를 잡을 수 있다. Text에 대해서 다음과 같이 계산한다.
2.3 Cross Attention
msa는 서로 다른 modality간에 interaction을 배울 기회를 제공한다. modality를 두 쌍씩 묶어서 co-attention matrix를 배운다.
2.4 Gating Mechanism for Cross Interaction
imperfect modality을 fusing하는 문제가 생기게 된다.
각 modality에서 발생하는 noise를 해결하기 위해서 선택적으로 cross fused vector를 배우기 위해 gating mechanism을 제안한다.
gated cross fused vector는 다음과 같이 얻는다.
여기서 fusion kernel fusion(,)은 gated combination of cross interaction과 contextual representation을 사용한다.
msa의 중요한 문제는 이러한 modalities에서 정보를 처리하는 joint representation을 추론하는 것이다.
그러나 지금까지의 연구는 이 joint representation을 얻기 위해서 모든 modalities가 input, result로 존재해야 했다.
test time에서 noisy나 missing에 민감햇다.
seq2seq가 기계번역 부분에서 성공을 거둔 것을 바탕으로 test time에서 모든 input modalities가 필요하지 않을 새로운 방법을 생각했다.
이번 논문에서 modalities간에 번역을 함으로써 joint representation을 배우는 방법에 대해서 소개한다.
이 방법은 source에서 target으로 번역을 해서 joint representation을 배우지만 source modalities만 input으로 필요하다는 것이 key point이다.
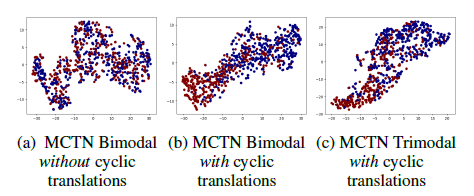
cycle consistency loss를 사용한다.
train 과정에서는 paired multimodal data가 필요하지만 test 과정에서는 source 만 있어도 된다.
항상 당연한 거지만 좋은 성능을 거두었다고 한다.
Introduction
text만 있던 sentiment analysis는 불충분한 면이 있었다. 그래서 최근에는 visual이나 acoustic같은 추가적인 정보를 사용해서 joint representation을 학습하고 있다.
위에서 말했던 것처럼 기존의 multimodal 방법들은 test time에도 모든 modalities가 필요했고, 이는 noisy나 missing modalities에 민감했다.
이 문제를 풀기 위해서 Seq2Seq의 최근 성공에서 영감을 받았다. 그래서 modalities 간에 번역을 함으로써 robust joint multimodal representation을 배우기 위해서 Multimodal Cyclic Translation Network model을 제안한다.
source modality에서 target modality로 번역하는 것이 intermediate representation을 얻을 수 있고, forward translations와 backward translation을 하는 cyclic translation loss를 사용한다.
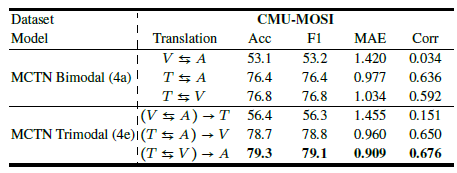
또한 이를 계층적으로 쌓아서 두 개의 modalities에서 세 개로 확장할 수 있다. MCTN의 다른 장점은 test 과정에서 source modality만 필요하다는 것이다. 그 결과로 robust한 특징을 가지게 된다.
Related Work
생략
Proposed Approach
Learning Joint Representation
XS 와 XT 사이에 Joint Representation은 εST=fθ(XS ,XT) embedding을 반환하는 parametrized function fθ로 정의된다. 그리고 다른 함수인 gw는 joint representation으로 label을 예측하는 함수다.
Train 과정에서는 θ 와 w가 다음과 같은 empirical risk minimization으로 학습된다.
source 에서 target으로의 번역이 XS 와 XT 사이의 joint information을 포착하는 intermediate representation을 만들어 낸다.
모든 modalities로 부터 maximal information를 가지는 joint representation을 배우도록 하기 위해 cycle consistency loss를 사용한다. 그리고 informative joint representations를 배우면서 input으로 source만 필요하도록 multimodal environment에서 back-translation를 사용한다. cycle consistency loss는 함수 fθ를 encoder와 decoder 부분으로 decomposing 함으로써 시작한다.
source 를 기준으로 보면 encoder는 다음과 같고,
decoder는 다음과 같다.
target으로 translated back을 하면 다음과 같다.
일반적으로 기계번역에서 사용하는 Seq2Seq를 multimodal 에서 사용하는 것이다.
encoder의 output은 다음과 같다.
decoder는 representation에서 target modality로 map 한다.
MCTN은 다음과 같은 식으로 best translation을 구한다.
test 과정에서 target modality에 대한 의존성을 제거하기 위해 forward translated representation을 추론에서 사용했다.
Coupled Translation - Prediction Objective
forward translation loss
cycle consistency loss
prediction loss
total loss
hyperparameter들은 이 total loss를 최소화하여 학습한다.
Hierarchical MCTN for Three Modalities
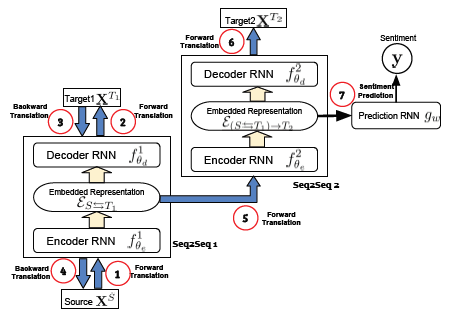
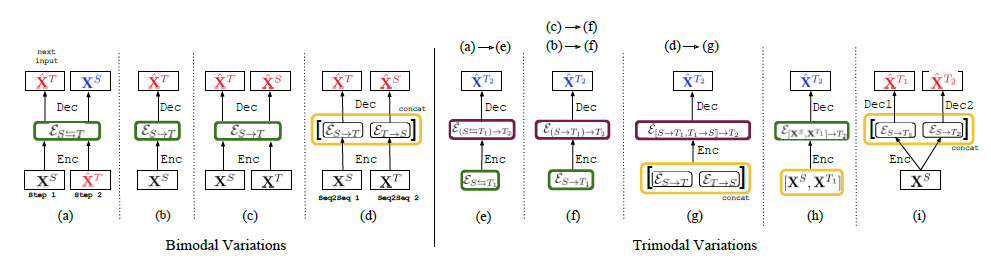
지금까지는 biomodal 이었던 것을 계층적인 구조로 확장해본다. XS에서 XT1,XT2로 넘어가도록 만드는 것이며, 처음에는 XS에서 XT1으로 번역하는 representation을 만들고, 두번째 단계에서는 여기서 얻은 representation에서 XT2로 번역을 한다. 그림으로 보면 다음과 같다.
Experimental Setup
Dataset and Input Modalities
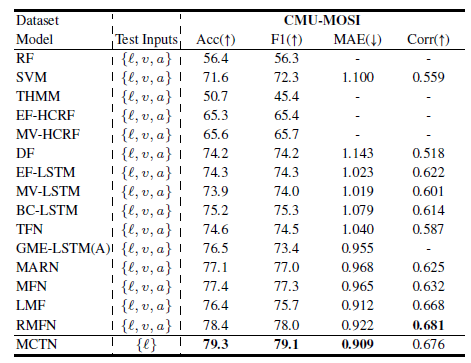
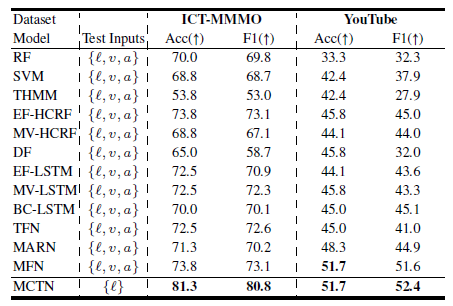
CMU-MOSI, ICT-MMMO, YouTube를 사용했다.
Multimodal Features and Alignment
Glove, Facet, COVAREP를 각 language, visual, acoustic 특징을 뽑아내는데에 사용했다.
Evaluation Metrics
CMU-MOSI에서는 MAE loss function을 사용했고, Acc, F1를 구했다.