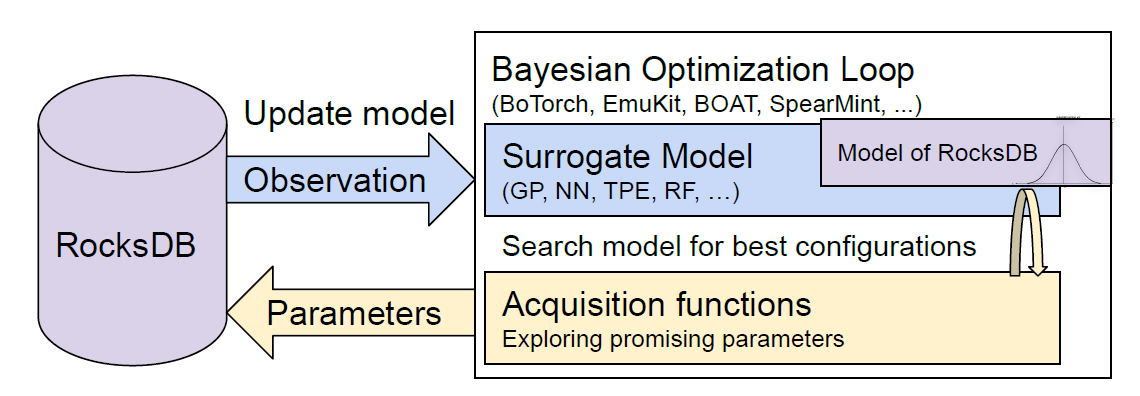
문제:
N×N크기의 땅이 있고, 땅은 1×1개의 칸으로 나누어져 있다. 각각의 땅에는 나라가 하나씩 존재하며, r행 c열에 있는 나라에는 A[r][c]명이 살고 있다. 인접한 나라 사이에는 국경선이 존재한다. 모든 나라는 1×1 크기이기 때문에, 모든 국경선은 정사각형 형태이다.
오늘부터 인구 이동이 시작되는 날이다.
인구 이동은 다음과 같이 진행되고, 더 이상 아래 방법에 의해 인구 이동이 없을 때까지 지속된다.
- 국경선을 공유하는 두 나라의 인구 차이가 L명 이상, R명 이하라면, 두 나라가 공유하는 국경선을 오늘 하루동안 연다.
- 위의 조건에 의해 열어야하는 국경선이 모두 열렸다면, 인구 이동을 시작한다.
- 국경선이 열려있어 인접한 칸만을 이용해 이동할 수 있으면, 그 나라를 오늘 하루 동안은 연합이라고 한다.
- 연합을 이루고 있는 각 칸의 인구수는 (연합의 인구수) / (연합을 이루고 있는 칸의 개수)가 된다. 편의상 소수점은 버린다.
- 연합을 해체하고, 모든 국경선을 닫는다.
각 나라의 인구수가 주어졌을 때, 인구 이동이 몇 번 발생하는지 구하는 프로그램을 작성하시오.
입력:
첫째 줄에 N, L, R이 주어진다. (1 ≤ N ≤ 50, 1 ≤ L ≤ R ≤ 100)
둘째 줄부터 N개의 줄에 각 나라의 인구수가 주어진다. r행 c열에 주어지는 정수는 A[r][c]의 값이다. (0 ≤ A[r][c] ≤ 100)
인구 이동이 발생하는 횟수가 2,000번 보다 작거나 같은 입력만 주어진다.
출력:
인구 이동이 몇 번 발생하는지 첫째 줄에 출력한다.
풀이방법:
**이 문제는 pypy3으로 통과했습니다.**
이 문제는 for(bfs)라고 생각했다. 우선 bfs를 사용한 이유는 한 나라로부터 인접한 국가들을 찾는 방법은 bfs가 가장 적당하다고 생각했기 때문이다. 하지만 이러한 bfs를 NxN 크기의 땅에 모두에 대해서 수행해야 했기 때문에 for(bfs)라고 생각했다. 그리고 이러한 문제때문에 시간초과가 발생할 수 있을 것 같다는 걱정이 들었는데, 실제로 python3으로는 시간초과가 발생하여서 pypy3으로 이 문제를 해결하였다.
bfs를 통해서 국경이 열리는 나라들을 찾으며 인구 수를 더하며 count를 센다. 한 번의 bfs 탐색이 끝나게 되면, 업데이트를 하는 과정을 거치고, 다시 이어서 bfs를 수행하도록 한다.
이러한 과정을 인구 이동이 발생하지 않을 때까지 반복한다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
|
dx = [-1, 0, 0, 1]
dy = [0, -1, 1, 0]
def move(countrys,openB):
change = False
for i in range(N):
for j in range(N):
if openB[i][j] == 0:
sum_ = countrys[i][j]
queue = [(i,j)]
total_queue = [(i,j)]
openB[i][j]=1
while len(queue):
tmp = []
for q in queue:
x,y = q
for idx in range(4):
nx = dx[idx] + x
ny = dy[idx] + y
if 0<= nx < N and 0 <= ny < N and openB[nx][ny]==0:
if L<= abs(countrys[nx][ny] - countrys[x][y]) <=R:
tmp.append((nx,ny))
sum_ += countrys[nx][ny]
openB[nx][ny] = 1
total_queue.extend(tmp)
queue = tmp
if len(total_queue) > 1:
change = True
avg = sum_//len(total_queue)
for x,y in total_queue:
countrys[x][y] = avg
return change, countrys
N, L, R = map(int,input().split())
countrys = []
for _ in range(N):
countrys.append(list(map(int,input().split())))
answer = 0
while True:
openB = [[0 for _ in range(N)] for _ in range(N)]
conti,countrys= move(countrys,openB)
if conti:
answer +=1
else:
break
print(answer)
|
cs |
문제링크:
https://www.acmicpc.net/problem/16234
16234번: 인구 이동
N×N크기의 땅이 있고, 땅은 1×1개의 칸으로 나누어져 있다. 각각의 땅에는 나라가 하나씩 존재하며, r행 c열에 있는 나라에는 A[r][c]명이 살고 있다. 인접한 나라 사이에는 국경선이 존재한다. 모
www.acmicpc.net
'Algorithm > Python' 카테고리의 다른 글
| [BOJ]5557. 1학년 (0) | 2021.07.13 |
|---|---|
| [BOJ]10973. 이전 순열 (0) | 2021.07.08 |
| [BOJ]14891. 톱니바퀴 (0) | 2021.07.01 |
| [BOJ]11725. 트리의 부모 찾기 (0) | 2021.06.29 |
| [BOJ]14725. 개미굴 (0) | 2021.06.22 |