전화번호 목록이 주어진다. 이때, 이 목록이 일관성이 있는지 없는지를 구하는 프로그램을 작성하시오.
전화번호 목록이 일관성을 유지하려면, 한 번호가 다른 번호의 접두어인 경우가 없어야 한다.
예를 들어, 전화번호 목록이 아래와 같은 경우를 생각해보자.
- 긴급전화 : 911
- 상근 : 97 625 999
- 선영 : 91 12 54 26
이 경우에 선영이에게 전화를 걸 수 있는 방법이 없다. 전화기를 들고 선영이 번호의 처음 세 자리를 누르는 순간 바로 긴급전화가 걸리기 때문이다. 따라서, 이 목록은 일관성이 없는 목록이다.
입력:
첫째 줄에 테스트 케이스의 개수 t가 주어진다. (1<=t<=50) 각 테스트 케이스의 첫째 줄에는 전화번호의 수 n이 주어진다. (1<=n<=10000) 다음 n개의 줄에는 목록에 포함되어 있는 전화번호가 하나씩 주어진다. 전화 번호의 길이는 길어야 10자리이며, 목록에 있는 두 전화번호가 같은 경우는 없다.
출력:
각 테스트 케이스에 대해서, 일관성 있는 목록인 경우에는 YES, 아닌 경우에는 NO를 출력한다.
풀이방법:
이전에 프로그래머스에서 이 문제를 풀었었지만, 그 때에는 단순히 반복문을 사용해서 풀었다면 이번에는 문자열에서 비교하는 자료구조인 Trie를 사용하도록 한다.
정보를 담을 Node 클래스와 이 Node들로 이루어진 Trie 클래스를 사용한다. Node의 key에는 알파벳, char 하나의 값이 들어가고, terminate는 이 Node가 마지막인지, 즉 string의 마지막인지를 나타내는 boolean 값이다. children은 더 이동할 수 있는 곳을 나타낸다.
함수로는 insert와 search 두 개가 있다. insert로 전화번호를 넣어주고 search로 일관성을 파악하도록 한다.
한 달 후면 국가의 부름을 받게 되는 준서는 여행을 가려고 한다. 세상과의 단절을 슬퍼하며 최대한 즐기기 위한 여행이기 때문에, 가지고 다닐 배낭 또한 최대한 가치 있게 싸려고 한다.
준서가 여행에 필요하다고 생각하는 N개의 물건이 있다. 각 물건은 무게 W와 가치 V를 가지는데, 해당 물건을 배낭에 넣어서 가면 준서가 V만큼 즐길 수 있다. 아직 행군을 해본 적이 없는 준서는 최대 K무게까지의 배낭만 들고 다닐 수 있다. 준서가 최대한 즐거운 여행을 하기 위해 배낭에 넣을 수 있는 물건들의 가치의 최댓값을 알려주자.
입력:
첫 줄에 물품의 수 N(1<=N<=100)과 준서가 버틸 수 있는 무게 K(1<=K<=100,000)가 주어진다. 두 번째 줄부터 N개의 줄에 거쳐 각 물건의 무게 W(1<=W<=100,000)와 해당 물건의 가치 V(0<=V<=1,000)가 주어진다.
원룡이는 한 컴퓨터 보안 회사에서 일을 하고 있다. 그러던 도중, 원룡이는 YESWOA.COM 으로부터 홈페이지 유저들의 비밀키를 만들라는 지시를 받았다. 원룡이는 비밀 키를 다음과 같은 방법으로 만들었다.
개인마다 어떤 특정한 소수 p와 q를 주어 두 소수의 곱 pq를 비밀 키로 두었다. 이렇게 해 두면 두 소수 p,q를 알지 못하는 이상, 비밀 키를 알 수 없다는 장점을 가지고 있다.
하지만 원룡이는 한 가지 사실을 잊고 말았다. 최근 컴퓨터 기술이 발달함에 따라, 소수가 작은 경우에는 컴퓨터로 모든 경우의 수를 돌려보아 비밀 키를 쉽게 알 수 있다는 것이다.
원룡이는 주성조교님께 비밀 키를 제출하려던 바로 직전에 이 사실을 알아냈다. 그래서 두 소수 p,q 중 하나라도 K보다 작은 암호는 좋지 않은 암호로 간주하여 제출하지 않기로 하였다. 이것을 손으로 직접 구해보는 일은 매우 힘들 것이다. 당신은 원룡이를 도와 두 소수의 곱으로 이루어진 암호와 K가 주어져 있을 때, 그 암호가 좋은 암호인지 좋지 않은 암호인지 구하는 프로그램을 작성하어야 한다.
입력:
암호 P(4<=P<=10^100)와 K (2<=K<=10^6)이 주어진다.
출력:
만약에 그 암호가 좋은 암호이면 첫째 줄에 GOOD을 출력하고, 만약에 좋지 않은 암호이면 BAD와 소수 r을 공백으로 구분하여 출력하는데 r은 암호를 이루는 두 소수 중 작은 소수를 의미한다.
풀이방법:
n보다 작은 소수를 찾아서 이를 P에다가 나눠본다. 이 때 나눠진다면 좋지 못한 암호이기 때문에 BAD와 그 수를 출력하면 된다. 이 때, K가 최대 10^6까지 가능하기 때문에 소수를 구하는 최적의 알고리즘이 필요할 것이라고 생각했고, 가장 효율적인 소수 알고리즘 중 하나인 에라토스테네스의 체를 사용했다.
길이가 K이고 값들이 1인 배열을 만들었고, 에라토스테네스의 체를 사용해서 소수를 구했다. 에라토스테네스의 체를 간단히 설명하면 한 소수 n의 배수들은 이 소수 n로 다 나눠질 것이기 때문에 소수가 아니라는 것이다.
따라서 해당하는 인덱스의 배열 값이 1이고, 소수라면 그 배수들의 배열값들을 다 0으로 만들어준다. 그리고 추후 탐색을 편하게 하기 위해서 인덱스를 answer 리스트에 담아둔다.
이렇게 하면 answer에는 소수만 남게 되고, 이를 P에다가 나눠보면서 좋은 암호인지 판단한다.
n이 완전수라면, n을 n이 아닌 약수들의 합으로 나타내어 출력한다. (예제 출력 참고).
이때, 약수들은 오름차순으로 나열해야 한다.
n이 완전수가 아니라면 n is NOT perfect. 를 출력한다.
풀이방법:
약수들을 찾는 것은 어렵지 않으나 출력 요건을 주의 깊게 맞춰야 하는 문제인 것 같다.
약수들을 찾는 것은 브루트포스 방법으로 2부터 다 나눠보면서 나머지가 없는 값을 찾으면 된다. 이 때, 조금이라도 시간을 줄이기 위해서 n까지 다 나눠보는 것이 아닌 n//2-1까지 나눠보도록 했다. 이렇게 약수들을 모두 찾은 다음에 중복을 제거한 다음에 정렬을 했다. (중복은 제곱수를 위해 제거, 9와 같은 경우 1,3,3과 같이 들어가 있을 것)
약수들의 합이 n과 같으면 완전수이므로 출력 조건에 맞춰서 출력을 하고, 다르면 n is NOT perfect.로 출력한다.
100,000미만의 완전수는 6, 28, 496, 8128만 있으니 확인 후 제출하면 된다.
문자열을 잘 parsing할 수 있는지와, 어느 시점에 최대가 되는지 알아야 하는 문제다.
우선 문자열을 파싱하기 위해서 splitTime이라는 함수를 만들었고, 날짜, 시간, 처리시간은 공백으로 구분되어 있기 때문에 split해주고, 날짜는 항상 2016년 9월 15일로 고정되어 있기 때문에 사용하지 않는다. 시간은 다시한번 :로 구분되어 있기 때문에 split해주고 1초간 처리하는 요청의 최대 개수를 알아야 하기 때문에 시간을 1초 단위로 만들어준다. 처리시간은 초 단위로 나오고 항상 s로 끝나기 때문에 이를 제거한 다음에 float으로 만들어 준다. 그리고 처리시간은 시작시간과 끝시간을 포함하기 때문에 배열로 반환을 할 때 시작시간에 0.001만큼 더하도록 한다.
보통 최대 개수인 부분은 시작시간이나 끝시간에서 발생하게 된다. 이 시간들을 기준으로 처리해야하는 데이터가 생성되거나 사라지기 때문이다. (배열의 모든 시간을 탐색해도 좋지만 시간이 오래 걸릴 것이다.) 각 트래픽별의 시작시간과 끝나는 시간을 기준으로 트래픽의 갯수를 세서 최대 갯수를 파악한다.
재난방재청에서는 많은 비가 내리는 장마철에 대비해서 다음과 같은 일을 계획하고 있다. 먼저 어떤 지역의 높이 정보를 파악한다. 그 다음에 그 지역에 많은 비가 내렸을 때 물에 잠기지 않는 안전한 영역이 최대로 몇 개가 만들어 지는 지를 조사하려고 한다. 이때, 문제를 간단하게 하기 위하여, 장마철에 내리는 비의 양에 따라 일정한 높이 이하의 모든 지점은 물에 잠긴다고 가정한다.
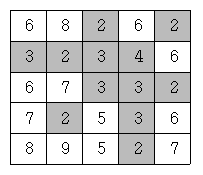
어떤 지역의 높이 정보는 행과 열의 크기가 각각 N인 2차원 배열 형태로 주어지며 배열의 각 원소는 해당 지점의 높이를 표시하는 자연수이다. 예를 들어, 다음은 N=5인 지역의 높이 정보이다.
이제 위와 같은 지역에 많은 비가 내려서 높이가 4 이하인 모든 지점이 물에 잠겼다고 하자. 이 경우에 물에 잠기는 지점을 회색으로 표시하면 다음과 같다.
물에 잠기지 않는 안전한 영역이라 함은 물에 잠기지 않는 지점들이 위, 아래, 오른쪽 혹은 왼쪽으로 인접해 있으며 그 크기가 최대인 영역을 말한다. 위의 경우에서 물에 잠기지 않는 안전한 영역은 5개가 된다.(꼭짓점으로만 붙어 있는 두 지점은 인접하지 않는다고 취급한다.)
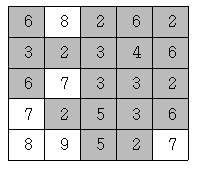
또한 위와 같은 지역에서 높이가 6이하인 지점을 모두 잠기게 만드는 많은 비가 내리면 물에 잠기지 않는 안전한 영역은 아래 그림에서와 같이 네 개가 됨을 확인할 수 있다.
이와 같이 장마철에 내리는 비의 양에 따라서 물에 잠기지 않는 안전한 영역의 개수는 다르게 된다. 위의 예와 같은 지역에서 내리는 비의 양에 따른 모든 경우를 다 조사해 보면 물에 잠기지 않는 안전한 영역의 개수 중에서 최대인 경우는 5임을 알 수 있다.
어떤 지역의 높이 정보가 주어졌을 때, 장마철에 물에 잠기지 않는 안전한 영역의 최대 개수를 계산하는 프로그램을 작성하시오.
입력:
첫째 줄에는 어떤 지역을 나타내는 2차원 배열의 행과 열의 개수를 나타내는 수 N이 입력된다. N은 2 이상 100 이하의 정수이다. 둘째 줄부터 N개의 각 줄에는 2차원 배열의 첫 번째 행부터 N번째 행까지 순서대로 한 행씩 높이 정보가 입력된다. 각 줄에는 각 행의 첫 번째 열부터 N번째 열까지 N개의 높이 정보를 나타내는 자연수가 빈 칸을 사이에 두고 입력된다. 높이는 1 이상 100 이하의 정수이다.
출력:
첫째 줄에 장마철에 물에 잠기지 않는 안전한 영역의 최대 개수를 출력한다.
풀이방법:
bfs를 사용해서 풀수는 있을 것 같지만 dfs를 사용해서 풀었다. 재귀의 깊이가 얼마나 될지 모르고, deepcopy를 사용하기 위해서 sys와 copy를 import 했다.
지역의 높이 정보 입력값을 받으면서 max 연산을 취해서 지역 내에 가장 높은 영역이 값을 얻도록 했다. (뒤에서 for 반복문에서 사용하기 위해) 입력을 다 받은 뒤에는 이 높이 정보를 deepcopy한 뒤 현재 rain에 맞게(1부터 시작한다.) 값을 빼주고 만약 0 이하로 떨어지게 된다면 0으로 만들고 나머지는 그대로 냅뒀다.
이제 이렇게 비에 잠긴 영역들을 표시했으니 dfs를 사용해서 살아있는 영역의 개수를 구한다. 각 점을 탐색하며 0이 아닌 곳에서 dfs 탐색을 시작하며 탐색 되는 곳은 0으로 만들어줘서 방문했음을 알려준다. 이렇게 반복해서 하면 영역의 개수를 구할 수 있고 max 연산을 통해 최댓값을 구한다.
어떤 파일 시스템에는 디스크 공간이 파일의 사이즈와 항상 같지는 않다. 이것은 디스크가 일정한 크기의 클러스터로 나누어져 있고, 한 클러스터는 한 파일만 이용할 수 있기 때문이다.
예를 들어, 클러스터의 크기가 512바이트이고, 600바이트 파일을 저장하려고 한다면, 두 개의 클러스터에 저장하게 된다. 두 클러스터는 다른 파일과 공유할 수 없기 때문에, 디스크 사용 공간은 1024바이트가 된다.
파일의 사이즈와 클러스터의 크기가 주어질 때, 사용한 디스크 공간을 출력하는 프로그램을 작성하시오.
입력:
첫째 줄에 파일의 개수 N이 주어진다. N은 1,000보다 작거나 같은 자연수이다. 둘째 줄에는 파일의 크기가 공백을 사이에 두고 하나씩 주어진다. 파일의 크기는 1,000,000,000보다 작거나 같은 음이 아닌 정수이다. 마지막 줄에는 클러스터의 크기가 주어진다. 이 값은 1,048,576보다 작거나 같은 자연수이다.
출력:
첫째 줄에 사용한 디스크 공간을 출력한다.
풀이방법:
파일을 클러스터에 넣으려고 할 떄 크게 3가지 경우가 발생한다.
1. 한 파일의 크기가 한 클러스터의 크기보다 큰 경우
2. 한 파일의 크기가 한 클러스터의 크기와 같은 경우
3.한 파일의 크기가 한 클러스터의 크기보다 작은 경우
그리고 위 3가지 case는 몫과 나머지를 통해서 구할 수 있다.
파일사이즈를 클러스터의 크기로 나눴을 때, 몫이 1보다 커지게 된다면 1의 케이스에 해당하며 몫만큼 클러스터의 개수를 준비하고 나머지가 있을 경우 하나 더 준비하면 된다.
그리고 몫이 0이라면 나머지가 있을 경우에는 한 개를 준비하면 되고, 나머지가 없다면 준비안하면 된다.