N개의 정수 A[1], A[2], ... , A[N]이 주어져 있을 때, 이 안에 X라는 정수가 존재하는지 알아내는 프로그램을 작성하시오.
입력:
첫째 줄에 자연수 N(1<=N<=100,000)이 주어진다. 다음 줄에는 N개의 정수 A[1], A[2], ... , A[N]이 주어진다. 다음줄에는 M(1<=M<=100,000)이 주어진다. 다음 줄에는 M개의 수들이 주어지는데, 이 수들이 A안에 존재하는지 알아내면 된다. 모든 정수들의 범위는 int로 한다.
출력:
M개의 줄에 답을 출력한다. 존재하면 1을, 존재하지 않으면 0을 출력한다.
풀이 방법:
binary_search를 사용하는 문제이다. python에 이진탐색을 지원하는 bisect라는 모듈이 있다. 따라서 이를 사용하면 쉽게 문제를 풀 수 있다. bisect의 모듈은 binary search를 직접적으로 지원을 하지 않기 때문에 따로 만들어줘야 한다. bisect에 bisect_left(arr,x)와 bisect_right(arr,x)가 있는데, 각각 arr에 x를 넣어야 할 때 어느 인덱스에 넣어야 할지 알려주는 함수이다.(left는 왼쪽에, right는 오른쪽에) 따라서 bisect_left를 사용하면 binary_search를 구현할 수 있다. 만약 기존 arr에 있는 값을 찾는다고 하면(넣으려고 한다면) 왼쪽 인덱스를 반환해주므로 원래의 위치를 return 해준다. 따라서 그 인덱스에 해당하는 배열 값과 x가 같으면 존재하고, 같지 않다면 존재하지 않다고 할 수 있다.
관계 데이터베이스 시스템의 뷰는 다른 릴레이션으로부터 유도된 릴레이션이다. 뷰를 사용함으로써 복잡한 질의를 간단하게 표현할 수 있고, 데이터 독립성을 높히기 위해서 사용한다.
ANSI/SPARC 3단계 아키텍처에서 외부 뷰 라는 개념이 있었는데 지금 설명하는 뷰는 다른 개념이다. 하나의 가상 릴레이션을 의미하며 기본 릴레이션에 대한 SELECT문의 형태로 정의된다.
View에는 3가지 종류가 있다.
Static view - base relation이 바뀌어도 view는 그대로 남아 있다. 변경시 수동으로 업데이트 해야 한다.
Dynamic view - base relation이 바뀐다면 view도 같이 바뀐다.
Materialized view - 위 view들이 논리적으로 실행되는 것과는 다르게 query 결과를 별도의 공간에 저장하고, query가 실행될 때 미리 저장된 결과를 출력함으로써 성능을 향상 시킨다.
어느 시점의 select문의 결과를 기본 릴레이션 형태로 저장해서 이를 사진을 찍은 것과 같아 snapshot이라고도 한다.
"CREATE VIEW 뷰이름[애트리뷰트] AS SELECT문 [WITH CHECK OPTION]" 과 같이 뷰를 정의한다.
뷰의 장점
1. 뷰는 복잡한 질의를 간단하게 표현할 수 있도록 한다. 뷰가 특정한 시점(조건)의 SELECT문을 정의한 것이므로 복잡하게 검색하는 질의를 뷰로 정의해두면 뷰는 SELECT하면 같은 값을 얻을 수 있다.
2. 뷰는 데이터 무결성을 보장하는데 활용된다. 처음 뷰를 정의할 때 설정한 조건을 기준으로 뷰를 갱신가능(추가, 수정)하다. 단 WITH CHECK OPTION을 명시했다고 가정한다. 따라서 뷰에 대한 갱신을 하면 기본 릴레이션에 대한 갱신으로 변환된다. 단 릴레이션의 기본 키가 포함되지 않은 뷰이다.
3. 뷰는 데이터 독립성을 제공한다. 뷰는 데이터베이스의 구조가 바뀌더라도 기존의 질의를 다시 작성할 필요가 없다. 예를 들어 하나의 릴레이션이 있고 이를 뷰로 정의했다고 하자. 알고보니 이 릴레이션을 두 개의 릴레이션으로 분해할 필요가 생겼고, 분해했다고 가정하자. 그러면 기존의 릴레이션으로 접근하던 질의는 분해된 릴레이션으로 바꿔야 하지만 뷰로 접근하도록 했다면 바꿀 필요가 없다.
4. 뷰는 같은 데이터라도 여러 가지 뷰를 제공할 수 있다. 특정한 시점의 SELECT문이라고 생각하면 되므로 여러가지 조건으로 뷰를 생성했다면 같은 데이터라도 서로 다른 뷰가 된다.
트랜잭션
트랜잭션은 동시성 제어를 지원하는데 동시성 제어란 동시에 수행되는 트랜잭션들이 데이터베이스에 미치는 영향이 순차적으로 수행할 때와 동일하도록 보장을 하는 것이다. 데이터베이스는 기본적으로 많은 사용자들이 동시에 접근하기 때문에 이를 보장할 필요가 있기 때문이다. 혹은 트랜잭션은 회복의 특징도 가지고 있는데 데이스베이스를 갱신하는 도중에 시스템이 고장 나도 일관성을 유지하는 것이다.
트랜잭션의 특성 (ACID)
원자성(Atomicity)
한 트랜잭션 내의 모든 연산들이 완전히 수행되거나 전혀 수행되지 않아야 함(all or noting)을 의미한다. 중간에 다운되어서 트랜잭션을 완료하지 못하였다면 취소를 하고, 완료된 트랜잭션은 재수행함으로써 원자성을 보장한다. 원자성은 DBMS의 회복과 연관되어 있다.
일관성(Consistency)
트랜잭션이 수행되기 전에 데이터베이스가 일관된 상태를 가졌다면 트랜잭션이 수행된 후에도 일관된 상태를 가진다. 일관성은 DBMS의 무결성 제약조건과 동시성 제어와 연관되어 있다.
고립성(Isolation)
한 트랜잭션이 데이터를 갱신하는 동안에 이 트랜잭션이 완료되기 전에는 갱신 중인 데이터를 다른 트랜잭션들이 접근하지 못하도록 해야 한다. 이를 확인하는 방법은 다수의 트랜잭션이 동시에 수행하더라도 결과는 어떤 순서로 수행한 것과 같아야 한다. 고립성은 DBMS의 동시성 제어와 연관되어 있다.
지속성(Durability)
한 트랜잭션이 완료되면 이 트랜잭션이 갱신한 것은 시스템이 고장나도 손실되지 않는다. 지속성은 DBMS의 회복과 연관되어 있다.
트랜잭션의 네 가지 특성과 DBMS의 기능과의 관계
완료(commit)와 철회(abort)
트랜잭션의 완료는 트랜잭션에서 변경하려는 내용이 데이터베이스에 완전하게 반영되었음을 의미하고 SQL상 COMMIT WORK이다. 트랜잭션의 철회는 변경하려는 내용이 일부만 반영된 경우에는 원자성을 보장하기 위해 트랜잭션 수행 전 상태로 되돌리는 것이다. SQL상 ROLLBACK WORK이다.
동시성 제어
대부분의 DBMS들은 다수 사용자용으로 설계되어 있고 여러 사용자들이 동시에 동일한 테이블을 접근하기도 한다. 따라서 성능을 높이기 위해 동시에 질의를 수행하는 것이 필수적이며, 부정확한 결과가 발생하지 않도록 해야한다. 동시성 제어를 설명하기에 앞서 필요한 개념의 정의다.
1. 직렬 스케줄
- 여러 트랜잭션들의 집합을 한 번에 한 트랜잭션씩 차례대로 수행한다.
2. 비직렬 스케줄
- 여러 트랜잭션들을 동시에 수행한다.
3. 직렬가능(serializable)
- 비직렬 스케줄의 결과가 어떤 직렬 스케줄의 수행 결과와 동등하다.
문제점
만약 동시성 제어를 하지 않고 다수의 트랜잭션을 동시에 수행한다면 다음과 같은 문제가 발생할 수 있다.
1. 갱신 손실: 수행 중인 트랜잭션이 갱신한 내용을 다른 트랜잭션이 덮어버려서 갱신이 무효가 되는 것이다.
T1
T2
X 와 Y의 값
read_item(X);
X=X-100000;
X=300000
Y=600000
read_item(X);
X=X+50000;
X=300000
Y=600000
write_item(X);
read_item(Y);
X=200000
Y=600000
write_item(X);
X=350000
Y=600000
Y=Y+100000;
write_item(Y);
X=350000
Y=700000
위와 같은 예시에서 X 값에 대해서 갱신 손실이 발생하게 되었다. 두 개의 트랜잭션에서 각각 X를 읽었고, 값을 갱신하였다. 하지만 T1에서 먼저 갱신을 했고 (X=X-100000-> 200000) T1이 쓰기 전에 그 다음 T2에서 갱신(X=X+50000-> 350000)을 했다. 따라서 같은 X의 데이터가 서로 다른 값을 가지게 되었고, T1이 write 한 다음에 T2가 write(덮어버렸다.)해서 갱신 손실이 발생하게 되었다.
2. 오손 데이터 읽기: 완료되지 않은 트랜잭션이 갱신한 데이터를 읽는 것이다.
T1
T2
UPDATE account
SET balance=balance-100000
WHERE cust_name='정미림';
SELECT AVG(balance)
FROM account;
ROLLBACK;
COMMIT
T1의 값을 COMMIT하기 전에 T2에서 갱신한 데이터를 접근해버려서 오손 데이터 읽기가 발생했다.
3. 반복할 수 없는 읽기: 한 트랜잭션이 동일한 데이터를 두 번 읽었으나 서로 다른 값을 읽게 되는 것이다.
T1
T2
SELECT AVG(balance)
FROM account;
UPDATE account
SET balance = balance - 100000
WHERE cust_name='정미림';
COMMIT;
SELECT AVG(balance)
FROM account;
COMMIT;
T2에서 AVG(balance)를 두 번 수행했는데 그 사이에 balance의 값의 갱신이 있었다. 따라서 반복할 수 없는 읽기 문제가 발생했다.
로킹(locking)
데이터 항목을 로킹하는 개념은 동시에 수행되는 트랜잭션들의 동시성을 제어하기 위해서 가장 널리 사용되는 기법이다. 로크는 데이터베이스 내의 각 데이터 항목과 연관된 하나의 변수이다. 트랜잭션에서 데이터 항목을 접근할 때 로크를 요청하고, 접근을 끝낸 후에 로크를 해제한다.
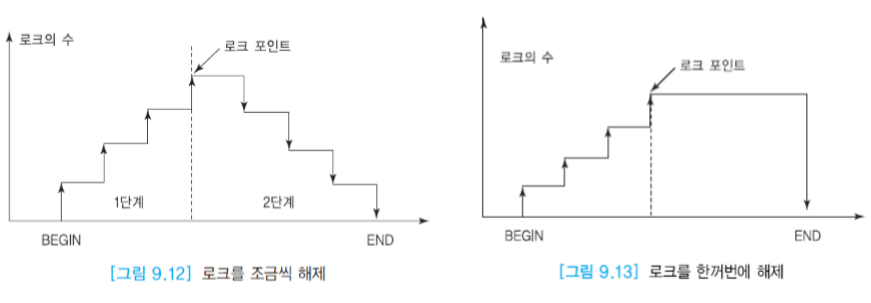
2단계 로킹 프로토콜
로크를 요청하는 것과 로크를 해제하는 것이 2단계로 이루어지는 것이다. 로크 확장하는 단계가 지난 후에 로크 수축 단계에 들어가게 되는 것이다.
팬텀 문제
두 개의 트랜잭션이 동일한 애트리뷰트드에 대해 갱신하는 작업을 수행한다고 하자. 그런데 하나의 트랜잭션에서 투플을 삭제하거나 삽입한다면 T1와 T2가 같은 SELECT를 하더라도 결과가 다르게 나타나게 되는데 이를 팬텀 문제라고 부른다. 즉 알 수 없는 값이 삭제되었거나 추가된 현상을 의미한다.
N X N 표에 수 N^2개 채워져 있다. 채워진 수에는 한 가지 특징이 있는데, 모든 수는 자신의 한 칸 위에 있는 수보다 크다는 것이다. N=5일 때의 예를 보자.
12
7
9
15
5
13
8
11
19
6
21
10
26
31
16
48
14
28
35
25
52
20
32
41
49
이러한 표가 주어졌을 때, N번째 큰 수를 찾는 프로그램을 작성하시오. 표에 채워진 수는 모두 다르다.
입력:
첫째 줄에 N(1<=N<=1,500)이 주어진다. 다음 N개의 줄에는 각 줄마다 N개의 수가 주어진다. 표에 적힌 수는 -10억보다 크거나 같고, 10억보다 작거나 같은 정수이다.
출력:
첫째 줄에 N번째 큰 수를 출력한다.
풀이 방법:
처음에는 모든 값을 다 담아서 n번 빼는 방식으로 했더니 메모리초과가 발생했다. N이 최대 1500까지 가능하니 1500^2개가 있으니 그럴만하다. 이 문제에서 원하는 것은 상위 N개를 원하는 것이다. 따라서 상위 N개만 담는 최소 힙을 만들고 모든 표를 다 본 뒤에 가장 작은 값을 찾으면 N번째 큰 수를 얻을 수 있다고 생각했다. heapq를 자세히 알아보니 heappop()으로 가장 작은 값을 빼낼 수 있지만 빼지 않고 arr[0]과 같이 접근 하면 가장 작은 값을 얻을 수 있다고 한다. 따라서 이를 이용해 answer에 가장 작은 값보다 큰 값이 들어오면 작은 값을 빼내고 큰 값을 넣는 방식으로 상위 N개 배열을 유지하였다.
이 문제는 애초에 pypy3으로 제출해서 python3에서 어떻게 동작할지는 잘 모르겠다.
널리 잘 알려진 자료구조 중 최대 힙(최소 힙)이라는 것이 있다. 최대 힙을 이용하여 다음과 같은 연산을 지원하는 프로그램을 작성하시오.
1. 배열에 자연수 x를 넣는다.
2. 배열에서 가장 큰(작은) 값을 출력하고, 그 값을 배열에서 제거한다.
프로그램은 처음에 비어있는 배열에서 시작하게 된다.
입력:
첫째 줄에 연산의 개수 N(1<=N<=100,000)이 주어진다. 다음 N개의 줄에는 연산에 대한 정보를 나타내는 정수 x가 주어진다. 만약 x가 자연수라면 배열에 x라는 값을 넣는(추가하는) 연산이고, x가 0이라면 배열에서 가장 큰 값을 출력하고 그 값을 배열에서 제거하는 경우이다. 입력되는 자연수는 2^31보다 작다.
출력:
입력에서 0이 주어진 회수만큼 답을 출력한다. 만약 배열이 비어 있는 경우인데 가장 큰 값을 출력하라고 한 경우에는 0을 출력하면 된다.
풀이 방법:
python에는 우선순위큐(힙)을 지원하는 heapq라는 모듈이 있다.python에서는 default로 최소 힙을 지원하기 때문에 최소 힙 문제에서는 모듈의 함수를 그대로 사용하면 되지만 최대 힙이나 절대값 힙과 같은 경우에는 별도의 스킬이 필요하다.
이 문제에서 사용하는 heapq의 함수는 heapify(), heappop(),heappush()가 있다. heapify(arr)는 일반 배열을 힙 구조를 가지는 배열로 만드는 함수로써 자동으로 배열 내 원소의 변동(추가, 삭제)가 있을 때마다 새로 힙 구조를 만든다. heappop(arr)는 arr에서 제일 위에 있는(제일 작은) 값을 빼내는 함수이고, heappush(arr,item)은 arr에 item을 넣고 힙 구조를 재배열하는 함수이다.
최소 힙을 최대힙으로 바꾸기 위해서 값을 넣을 때 그냥 값을 넣는 것이 아니라 (-item,item)과 같은 방식으로 값을 넣는다. 힙 구조를 -item을 기준으로 정렬한다. 단순히 생각하면 "최소 힙으로 정렬한 것을 뒤집었다"라고 생각하면 된다. 따라서 이렇게 값을 넣었으므로 뺀 뒤에 [1]과 같은 방식으로 값을 접근해야 원래의 값을 얻는다.
최대 힙과 같은 방식으로 절대값 힙도 (abs(item),item)으로 정렬하면 된다.
또한 python3로 제출하면 시간초과가 발생해서 pypy3로 제출해서 시간초과문제를 해결하였습니다.
[2019.07.29 수정] 문제가 재채점 되었더니 시간초과가 발생하였다. 따라서 input() -> sys.stdin.readline().rstrip() 으로 바꾸어서 해결하였다. (import sys 필요)
신종 바이러스인 웜 바이러스는 네트워크를 통해 전파된다. 한 컴퓨터가 웜 바이러스에 걸리면 그 컴퓨터와 네트워크 상에서 연결되어 있는 모든 컴퓨터는 웜 바이러스에 걸리게 된다.
예를 들어 7대의 컴퓨터가 <그림1>과 같이 네트워크 상에서 연결되어 있따고 하자. 1번 컴퓨터가 웜 바이러스에 걸리면 웜 바이러스는 2번과 5번 컴퓨터를 거쳐 3번과 6번 컴퓨터까지 전파되어 2,3,5,6 네 대의 컴퓨터는 웜 바이러스에 걸리게 된다. 하지만 4번과 7번 컴퓨터는 1번 컴퓨터와 네트워크상에서 연결되어 있지 않기 때문에 영향을 받지 않는다.
어느 날 1번 컴퓨터가 웜 바이러스에 걸렸다. 컴퓨터의 수와 네트워크 상에서 서로 연결되어 있는 정보가 주어질 때, 1번 컴퓨터를 통해 웜 바이러스에 걸리게 되는 컴퓨터의 수를 출력하는 프로그램을 작성하시오,
입력:
첫째 줄에는 컴퓨터의 수가 주어진다. 컴퓨터의 수는 100 이하이고 각 컴퓨터에는 1번 부터 차례대로 번호가 매겨진다. 둘째 줄에는 네트워크 상에서 직접 연결되어 있는 컴퓨터의 쌍의 수가 주어진다. 이어서 그 수만큼 한 줄에 한 쌍씩 네트워크 상에서 직접 연결되어 있는 컴퓨터의 번호 쌍이 주어진다.
출력:
1번 컴퓨터가 웜 바이러스에 걸렸을 때, 1번 컴퓨터를 통해 웜 바이러스에 걸리게 되는 컴퓨터의 수를 첫째 줄에 출력한다.
풀이 방법:
1에 연결되어 있는 네트워크를 다 찾아야 하므로 깊게 계속 파고 들어가는 것 보다 너비를 우선 해서 탐색하는 편이 더 좋다. 우선 양방향으로 퍼질 수 있으므로 인덱스를 컴퓨터의 번호로 해서 리스트로 이동할 수 있는 컴퓨터를 담아두었다. 그 다음에는 answer리스트를 만들어두고 answer에는 없지만 갈 수 있는 곳이면 answer에 담고 이동을 하는 방식으로 답을 구하였다. 1번 컴퓨터를 제외한 컴퓨터의 수가 정답이므로 마지막에 1을 뺐다.
그래프를 DFS로 탐색한 결과와 BFS로 탐색한 결과를 출력하는 프로그램을 작성하시오. 단, 방문할 수 있는 정점이 여러 개인 경우에는 정점 번호가 작은 것을 먼저 방문하고, 더 이상 방문할 수 있는 점이 없는 경우 종료한다. 정점 번호는 1번부터 N번까지이다.
입력:
첫째 줄에 정점의 개수 N(1<=N<=1,000), 간선의 개수 M(1<=M<=10,000), 탐색을 시작할 정점의 번호 V가 주어진다. 다음 M개의 줄에는 간선이 연결하는 두 정점의 번호가 주어진다. 어떤 두 정점 사이에 여러 개의 간선이 있을 수 있다. 입력으로 주어지는 간선은 양방향이다.
출력:
첫째 줄에 DFS를 수행한 결과를, 그 다음 줄에는 BFS를 수행한 결과를 출력한다. V부터 방문된 점을 순서대로 출력하면 된다.
풀이 방법:
양방향으로 이동가능이 하므로 2중배열로 만들어서 경로를 저장했다. 인덱스가 출발하는 정점이고 그 안에 들어있는 값들은 도착하는 정점이다.
DFS는 지금 마지막으로 들어온 정점이 중요하므로 그 정점이 가지고 있는 경로 중에 지나지 않은 곳으로 다시 들어가는 재귀방식으로 짜주면 된다.
BFS는 계속해서 배열을 누적하는 방식으로 진행했다. BFS에 계속 담아두고 반복문으로 하나하나 탐색하며 방문하지 않은 정점으로 이동하는 방식으로 진행했다. BFS에는 예외처리 구문이 들어가 있다. 왜냐하면 처음에는 없이 했더니 런타임에러가 발생하게 되었고, 그 이유를 알아보니 시작하는 정점이 1이라고 줬지만 1로 시작하는 정점이 없을 때 문제가 발생했다. 따라서 이 문제를 해결하기 위해 예외처리구문을 넣었다.
프로젝트를 진행하다 보면 코드를 자주 수정하게 되고 그 코드를 저장하게 된다. 이럴 때마다 '하나의 버전이 생겼다.'라고 한다. (게임의 패치 버전과 같다고 생각하면 된다.) 버전을 나누면서 코드를 관리한다면 얻을 수 있는 장점이 많다. 만약 프로젝트를 진행하다가 실수로 파일을 지우게 되었다거나 컴퓨터가 고장이 난다면 다시 이 파일을 복구할 수 없는 방법이 없다. 또한 내가 계속해서 진행하던 프로젝트 방향이 옳지 못한 방향일 수도 있을 것이다. 버전을 나눠서 관리하지 않았다면 다시 이전으로 돌아갈 수 (undo) 없었을 것이다. 하지만 버전을 나눠서 관리해 저장했다면 필요한 버전으로 돌아가서 다시 진행하면 될 일이다. 따라서 버전을 나눠서 관리를 해야 한다.
그러면 매번 다른 이름으로 저장하기를 해서 버젼명을 적어주면 되지 않을까 생각할 수 있다. 하지만 대부분의 경우에는 프로젝트는 팀으로 진행하는 경우가 많다. 아무리 자주 버전을 자주 공유한다고 해도 같은 버전의 파일을 수정하고 있을 수도 있고, 서로 진행한 방향이 맞지 않아서 충돌이 발생할 수 있을 것이다. 그렇다고 해서 서로 시간을 나눠가며 프로젝트를 진행하기에는 매우 비효율적이다. 따라서 위의 문제를 모두 해결하기 위해 생겨난 것이 VCS(Version Control System)이다.
VCS는 각 사용자들은 repositories라는 저장소를 가지고 있다. (CVS) 그리고 서로 공유하는 repository(git)를 만들어 자re신의 repo에 있는 파일들을 git의 repo에 올리고 내려받으면서 버전을 관리하겠다는 시스템이다.
메일로 코드를 공유하는 것과 차이를 두기 위해서 Branching이라는 개념이 존재한다. 같은 repository안에 서로 다른 가지(branch)를 만들어서 서로 코드를 관리하고 나중에 이를 서로 merge를 해서 합칠 수 있도록 했다.
Git의 기본 개념
Git을 본격적으로 사용하기에 앞서서 몇가지 개념을 알고 있어야 한다. git에는 크게 세 가지의 공간이 있다.
local repository입니다.
1. working directory : 사용자가 실제로 작업을 하는 공간이다. 이 공간에서 파일을 수정, 추가, 삭제를 할 수 있다.
2. staging area : working directory에서 바뀐 상태(수정, 추가, 삭제)를 이 공간으로 올린다. (add 한다.)
3. git directory : staging area에 올린 상태들을 repository에 올림으로써 하나의 버전을 등록하게 된다. (commit 한다.)
git은 각 버젼에 대해 checksum을 만들어 놓았기 때문에 이전의 버전으로 돌아가는 것이 쉽다.
Git의 기본적인 흐름
Git을 사용하는 기본적인 흐름은 다음과 같다.
1. Init a repo
우선 repository를 만들어야 한다. 따라서 내가 만들고 싶은 파일에서 우클릭을 해서 Git Bash를 사용해서 git command 창에 들어오고 이 창에 git init을 쳐서 repository를 만들도록 한다.
위와 같이 .git 파일이 만들어졌다면 성공
위 사진과 같이 .git 폴더가 만들어졌다면 성공적으로 repository를 만들게 되었다.(숨김 파일을 보이기로 설정해야 한다.)
2. Edit files
.git이 있는 폴더 내에서 새로운 파일을 하나 만들어 보도록 하자. 즉 working directory에 새로운 파일을 만든다는 것이다.
아무 파일이나 하나 만들거나 가져와보자.
3. Stage the changes and Review your changes
지금은 working directory에 있는 것이고 이를 staging area에 올려야 한다. 이를 확인하는 간단한 방법은 git status 명령어를 사용하는 것이다. git status를 사용하면 아래 왼쪽 사진과 같이 Untracked files 라며 staging area에 올려야 한다고 빨간 글씨로 알려준다.
따라서 이 파일을 staging area에 올리기 위해서는 git add <filename> 명령어를 사용해야 한다. 이 예시에서는 git add test.txt 와 같이 입력을 하였고, 이 명령어를 수행하고 나서 git status를 다시 쳐보니 초록색 글씨로 staging area에 올라와 있음을 알려준다. (오른쪽 사진)
[좌] add 하기 전, [우] add 한 후
4. Commit the changes
이제 이 staging area에 있는 것을 repository에 올려야 하는데 이는 git commit 명령어를 사용한다. git commit 명령어를 사용하게 되면 commit message를 입력하라고 초기 설치했던 편집기로 이동하게 될 것이다.
commit message는 repository에 등록을 할 때 어떠한 점이 바뀌었는지 간단히 써준다고 생각하면 된다.
따라서 우측 사진처럼 message를 입력하고 저장버튼을 누르고 닫는다면 commit이 완료될 것이다.
[좌] git commit 명령어 [우] commit message 입력하기
만약 이렇게 편집기를 통해서 message를 입력하는 것이 귀찮다면 git commit -m "<message 내용>"을 통해서 위와 같은 작업을 수행할 수 있다. 이후 git status를 다시 입력하면 깔끔하게 staging area가 비워진 모습을 얻을 수 있을 것이다.
지금까지 Git의 기본적인 흐름이었으며 이 큰 틀은 거의 바뀌지 않는다. 하지만 Git을 잘 사용하기 위해서는 branch를 잘 다뤄야 하며 다음 편에서는 branch와 관련된 명령어를 소개하겠습니다.
릴레이션 R에서 애트리뷰트 B가 애트리뷰트 A에 함수적으로 종속하면서 애트리뷰트 A의 어떠한 진부분 집합에도 함수적으로 종속하지 않으면 애트리뷰트 B가 애트리뷰트 A에 완전하게 함수적으로 종속한다고 말한다. 즉, 애트리뷰트 B는 릴레이션 내 결정자들에 의해 결정되는 것임을 의미한다. (여기서 A는 복합 애트리뷰트이다.)
2. 부분 함수적 종속성
부분 함수적 종속성은 완전 함수적 종속성이 아닌 함수적 종속성들을 의미한다.
3. 이행적 함수적 종속성
한 릴레이션의 애트리뷰트 A, B, C가 주어졌을 때 애트리뷰트 C가 이행적으로 A에 종속한다.(A->C)는 것의 필요충분조건은 A->B ^ B->C 가 성립하는 것이다. 즉 3단 논법을 만족하는 함수적 종속성을 의미한다.
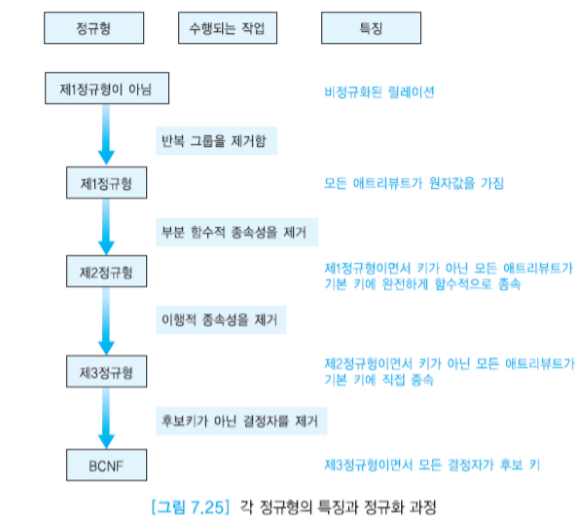
정규화
정규형의 종류에는 제1 정규형, 제2정규형, 제3정규형, BCNF, 제4정규형, 제 5정규형이 있으나 일반적으로 BCNF까지만 고려한다.
제1정규형
한 릴레이션 R이 제1 정규형을 만족할 필요충분조건은 릴레이션 R의 모든 애트리뷰트가 원자값만을 가진다는 것이다. 즉 애트리뷰트에 반복 그룹이 나타나지 않는다면 제1 정규형을 만족한다.
제1정규형을 사용해 문제를 해결한 예시
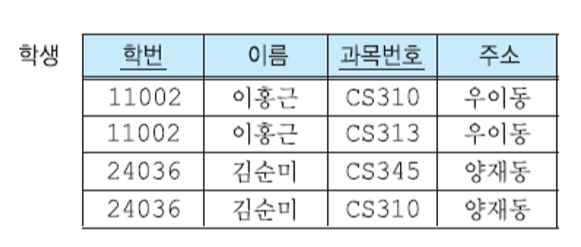
하지만 제1 정규형을 진행해도 갱신 이상이 존재할 수 있다. 아래 그림의 학생 릴레이션은 모든 애트리뷰트가 원자값을 가지므로 제 1정규형을 만족한다. 이 릴레이션의 기본 키는 (학번, 과목 번호)이다.
문제가 있는 제 1정규형
1. 수정 이상
- 한 학과에 소속한 학생 수만큼 그 학과의 전화번호가 중복되어 저장되므로 여러 학생이 소속된 학과의 전화번호가 변경되었을 때 모든 학생들의 투플에서 전화번호를 수정하지 않으면 수정 이상이 발생한다.
2. 삽입 이상
- 한 명의 학생이라도 어떤 학과에 소속되지 않으면 학과에 관한 투플을 삽입할 수 없다. 학번이 기본 키의 구성요소인데 엔티티 무결성 제약조건에 의해 기본 키에 널 값을 넣을 수 없기 때문이다.
3. 삭제 이상
- 어떤 학과에 소속된 마지막 학생을 삭제한다면 이 학생이 소속된 학과의 정보도 삭제된다.
why? 기본 키에 대한 부분 함수적 종속성이 있기 때문에 갱신 이상이 발생한다.
제2 정규형
제1 정규형을 만족하는 릴레이션에 대해서 어떤 후보 키에도 속하지 않는 애트리뷰트들이 R의 기본 키에 완전하게 함수적으로 종속하는 것을 의미한다. 따라서 위의 갱신 이상을 해결하기 위해서 학생 릴레이션을 학번 1, 수강 릴레이션으로 분해할 수 있다.
제1 정규형에서 제 2정규형으로의 분해
따라서 위와 같이 분해한다면 아래와 같은 기본 키가 학번인 학생 1 릴레이션이 생기게 될 것이다. 하지만 제2정규형을 진행해도 아직 갱신 이상이 남아있다.
제 2정규형에도 문제가 발생
1. 수정 이상
- 여러 학생이 소속된 학과의 전화번호가 변경된다면 그 학과에 속한 모든 학생들의 투플에서 전화번호를 수정해야 일관성이 유지된다.
2. 삽입 이상
- 어떤 학과가 신설해서 소속 학생이 없다면 정보를 입력할 수 없다.
3. 삭제 이상
- 어떤 학과에서 마지막 학생의 투플이 삭제된다면 학과의 전화번호도 함께 삭제된다.
why? 학생1 릴레이션에 이행적 종속성이 존재하기 때문에 갱신 이상이 발생한다.
제3 정규형
한 릴레이션 R이 제2 정규형을 만족하면서, 키가 아닌 모든 애트리뷰트가 R의 기본키에 이행적으로 종속하지 않는 것을 의미한다. 따라서 학생 1에 존재하는 이행적 종속성을 해결하기 위해서 학생 2, 학과 릴레이션으로 분해한다.
제3정규형으로의 분해
이제 학생 릴레이션에서는 더 이상 갱신 이상이 발생하지는 않으므로 정규화 작업이 필요하지 않다. 하지만 제2 정규형에서 생성된 수강 릴레이션에서 갱신 이상이 발생되므로 이 릴레이션에 대해서는 추가 정규화 작업이 필요하게 된다.
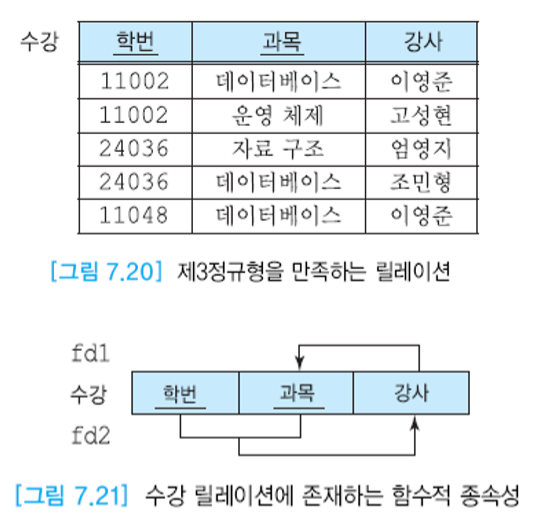
수강 릴레이션에서 각 학생은 여러 과목을 수강할 수 있고, 각 강사는 한 과목만 가르치게 된다. 이 릴레이션의 기본 키는 (학번, 과목)이다. 키가 아닌 강사 애트리뷰트가 기본 키에 완전하게 함수적으로 종속하므로 제2 정규형을 만족하고, 강사 애트리뷰트가 기본 키에 직접 종속하므로 제3 정규형도 만족한다.
따라서 이 릴레이션에는 아래와 같은 함수적 종속성이 존재한다.
(학번, 과목) -> 강사, 강사-> 과목
1. 수정 이상
- 여러 학생이 수강 중인 어떤 과목의 강사가 변경되었을 때 그 과목을 수강하는 모든 학생들의 투플에서 강사를 수정해야 한다.
2. 삽입 이상
- 어떤 과목을 신설해서 아직 수강하는 학생이 없으면 어떤 강사가 그 과목을 가르친다는 정보를 입력할 수 없다. 이 역시도 엔티티 무결성 제약조건에 의해 기본 키를 구성하는 애트리뷰트에 널 값을 넣을 수 없다는 이유 때문이다.
3. 삭제 이상
- 어떤 과목을 이수하는 학생이 한 명밖에 없는데 이 학생의 투플을 삭제하면 그 과목을 가르치는 강사에 관한 정보도 함께 삭제된다.
why? 수강 릴레이션에서 키가 아닌 애트리뷰트가 다른 애트리뷰트를 결정하기 때문에 갱신 이상이 발생한다.
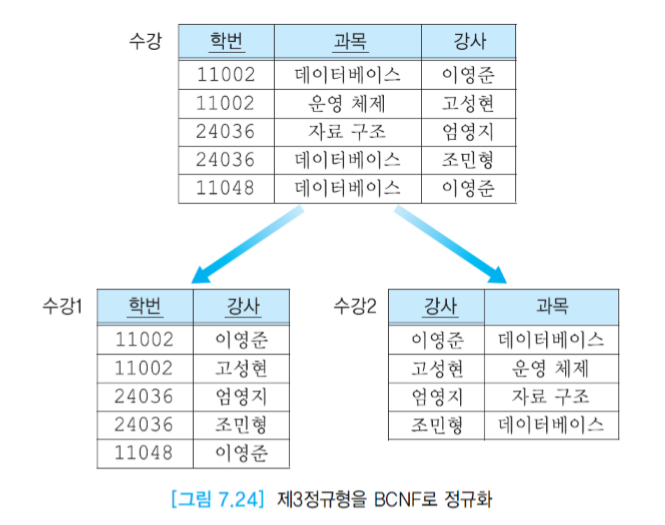
BCNF
릴레이션 R이 제3 정규형을 만족하고, 모든 결정자가 후보 키여야 한다. 수강 릴레이션에서 강사는 후보 키가 아님에도 불구하고 과목을 결정하기 때문에 문제가 발생했던 것이다.
BCNF를 하기 위해서 키가 아니면서 결정자 역할을 하는 애트리뷰트(강사)와 그 결정자에 함수적으로 종속하는 애트리뷰트(과목)를 하나의 테이블에 넣는다. 이 릴레이션에서는 강사가 기본 키가 된다. 그다음에는 기존 릴레이션에 결정자(강사)를 남겨서 기본 키의 구성요소가 되도록 한다. (-> 외래 키가 된다)
위의 과정들을 요약을 하면 다음과 같다.
정규화의 장점은 정규화를 진행할수록 중복이 감소하고, 갱신 이상도 감소된다. 정규화가 진전될수록 무결성 제약조건을 시행하기 위해 필요한 코드의 양이 감소된다.
하지만 높은 정규형을 만족한다고 해서 릴레이션 스키마가 최적이 되는 것은 아니다. 분해되기 전의 릴레이션의 내용이 필요하다면 조인의 필요성이 증가하기 때문에 더 안 좋아질 수도 있다.
N장의 카드가 있다. 각각의 카드는 차례로 1부터 N까지의 번호가 붙어 있으며, 1번 카드가 제일 위에, N번 카드가 제일 아래인 상태로 순서대로 카드가 놓여 있다.
이제 다음과 같은 동작을 카드가 한 장 남을 때까지 반복하게 된다. 우선, 제일 위에 있는 카드를 바닥에 버린다. 그 다음, 제일 위에 있는 카드를 제일 아래에 있는 카드 밑으로 옮긴다.
예를 들어 N=4인 경우를 생각해 보자. 카드는 제일 위에서부터 1234의 순서로 놓여있다. 1을 버리면 234가 남는다. 여기서 2를 제일 아래로 옮기면 342가 된다. 3을 버리면 42가 되고, 4를 밑으로 옮기면 24가 된다. 마지막으로 2를 버리고 나면, 남는 카드는 4가 된다.
N이 주어졌을 때, 제일 마지막에 남게 되는 카드를 구하는 프로그램을 작성하시오.
입력:
첫째 줄에 정수 N(1<=N<=500,000)이 주어진다.
출력:
첫째 줄에 남게 되는 카드의 번호를 출력한다.
풀이 방법:
처음에는 카드 방식대로 일반 배열의 pop을 이용해서 문제를 풀었더니 시간초과가 발생하였다. 이를 줄이기 위해서 문제 케이스가 계속 짝수만 남게 되는 구조인것 같아 짝수만 담아서 했는데 틀렸었다. 따라서 애초 문제 의도대로 큐 모듈을 가져와서 풀었더니 시간 초과 없이 통과하였다.
파이썬은 queue를 지원하는 모듈을 가지고 있다. queue.Queue()는 한 변수를 큐 배열로 선언하겠다는 뜻이다. 그리고 이렇게 큐로 선언한 배열에 put()은 값을 넣는 함수, qsize()는 길이를 반환하는 함수, get()은 값을 빼는 함수들을 사용할 수 있다. 따라서 이렇게 pop()을 쓴 것 처럼 똑같이 짜면 시간초과 없이 통과 가능하다.
세계는 균형이 잘 잡혀있어야 한다. 양과 음, 빛과 어둠 그리고 왼쪽 괄호와 오른쪽 괄호처럼 말이다.
정민이의 임무는 어떤 문자열이 주어졌을 때, 괄호들의 균형이 잘 맞춰져 있는지 판단하는 프로그램을 짜는 것이다.
문자열에 포함되는 괄호는 소괄호 ("()") 와 대괄호 ("[]")로 2종류이고, 문자열이 균형을 이루는 조건은 아래와 같다.
* 모든 왼쪽 소괄호는 ("(")는 오른쪽 소괄호(")")와만 짝을 이룰 수 있다.
* 모든 왼쪽 대괄호는 ("[")는 오른쪽 대괄호("]")와만 짝을 이룰 수 있다.
* 모든 오른쪽 괄호는 자신과 짝을 이룰 수 있는 왼쪽 괄호가 존재한다.
* 모든 괄호들의 짝은 1:1 매칭만 가능하다. 즉, 괄호 하나가 둘 이상의 괄호와 짝지어지지 않는다.
* 짝을 이루는 두 괄호가 있을 때, 그 사이에 있는 문자열도 균형이 잡혀야 한다.
정민이를 도와 문자열이 주어졌을 때 균형잡힌 문자열인지 아닌지를 판단해보자.
입력:
하나 또는 여러줄에 걸쳐서 문자열이 주어진다. 각 문자열은 영문 알파벳, 공백, 소괄호 ("()") 대괄호("[]")등으로 이루어져 있으며, 길이는 100글자보다 작거나 같다.
입력의 종료조건으로 맨 마지막에 점 하나(".")가 들어온다.
출력:
각 줄마다 해당 문자열이 균형을 이루고 있으면 "yes"를, 아니면 "no"를 출력한다.
풀이 방법:
처음에는 이와 비슷한 문제들은 ( , [ 를 만나면 count +=1 하고 ), ]를 만나면 count -=1 하는 방법으로 쉽게 풀 수 있어서 비슷한 문제인 줄 알았다. 하지만 예제 중에 5번째 줄인 ( [ ) ] 과 같은 케이스는 마지막 조건에 의해서 안된다는 것을 알게 되었다.
따라서 이 문제를 해결하기 위해서 stack이라는 배열을 만들어서 ( , [를 만나면 담고, ) ] 를 만나면 빼는 ( 예외 케이스 처리 하에) 방법으로 해서 통과를 했다.