Lecture 2
- Generalization
- Speed of Convergence for Training and Learning quality
Performance Generalization
Neural network는 두 가지 중요한 점을 충족시켜야 한다.
- training data를 통해서 학습하기 때문에, training data에 대해서는 정확하게 분류해야 한다.
- learning process에 대해서 generalize하기 위해서 이전에 보지 못한 데이터(test data)에 대해서도 잘 분류해야 한다.
복잡한 결정 경계선(면)을 가지고 있다고 해서 이 것이 좋은 generalization performance를 가지고 있다고 하지 않는다.
실험 과정에서는 다음과 같이 진행된다.
- data set을 Learning set(85%)과 test set(15%)으로 구분한다.
- Learning set을 training set(70%)와 validation set(15%)로 구분을 한다.
- training set으로 network을 훈련을 하고, training set과 validation set으로 성능을 평가한다.
만약 training error가 높다면 underfitting이 발생한 것이고, training error가 낮지만 validation error가 높으면 overfitting, 둘 다 낮은 수치가 나온다면 generalization이 잘 일어난 것을 의미한다.
위에서 했던 것에서 더 발전시켜서 3번을 서로 다른 구조로 진행한다.
- 3번의 여러 구조에서 over and underfit이 아닌 best network을 고른다.
- 다른 model인 것이 아니라 parameter tuning을 하는 것
- 이를 learning set으로 다시 훈련을 한다.
- test set으로 generalization을 테스트 한다.
- three subset을 바꿔가면서 N번 반복하는 것을 N-fold cross validation protocol이라고 한다.
- 하지만 각 parameter별로 best value가 다르다면...?
Parameter search
- training set으로 다른 parameter들을 train하고, validation으로 평가한다.
- 각 parameter에 대해서 errorval을 기록한다.
- training set과 validation set을 reshuffle을 해서 1과 2를 반복한다.
- 3번을 n times 반복한다.(n-fold CV)
- n-fold로 부터 얻은 errorval 평균내고, 작은 평균 errorval을 가진 것들을 모아서 best parameter set을 만든다.
- Parameter searching 전략에는 다음 두 가지가 있다.
- Grid Search
- q개의 파라미터가 있고, 각 파라미터당 p개의 value가 생긴다면 이 경우에 대해서 모두 탐색하는 것을 의미한다.
- mpq개다.
- Random Search
- parameter value들을 random combination으로 진행한다.
- grid search보다 좋은 점은 each parameter마다 unique한 value를 얻을 수 있기 때문에 좋다??
- Grid Search
Generalization
generalization을 위해서 적절한 모델을 고르는 것도 중요하지만 다른 방법들에는 어떠한 것이 있을 까?
1. Enrich Training data
적은 데이터를 가지고 있으면, 모델은 쉽게 수렴할 수 있다.(small training error) 적은 데이터를 모델이 전부 외어버린다고 생각하면 된다. 하지만 절대적인 정보의 양이 부족하기 때문에 나쁜 generalization을 가진다.(large training error)
거대한 데이터라면 모델이 이를 학습하기 위해서 더 많은 노력을 해야 한다. (higher training error) 대신 정보의 양이 충분해졌기 때문에 더 좋은 generalization 성능을 가질 것이다.(lower test error)
즉, 질이 좋고 많은 양의 데이터를 사용해야 overfitting을 방지할 수 있다. 하지만, 이러한 데이터를 구하는 것은 많은 비용이 들고, 힘들다.
그래서 인공적으로 training data를 늘리는 방법을 사용하는데, 이를 Data augmentation이라고 부른다. (translation, rotation, stretching, shearing, lens distortions...)
2. Early stopping
훈련을 진행할 때, 언제 멈추는 것이 좋을까? 훈련을 계속해서 진행을 한다면 zero training error를 달성할 수 있을 것이다. 하지만 이는 train data에 overfitting 된 상태이기 때문에 test error는 매우 높을 것이다. 따라서 validation error를 기준으로 early stopping 할 포인트를 구한다.
3. Ensemble
여러 Network를 동시에 훈련을 시키고, 이들의 average를 사용하는 방법이다.
4. Regularization
network의 complexity를 줄이는 방법이다.
L2(weight decay)
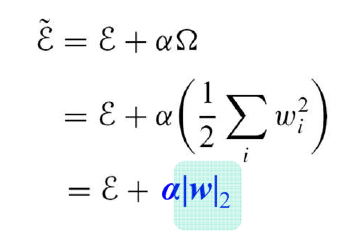
- 각각의 벡터에 대해 항상 unique한 값을 반환
L1

- 특정 feature가 없어도 같은 값을 반환
- feature selection이 가능하다.
- Sparse model이 적합하다.
- 미분 불가능한 점이 있기 때문에 gradient에 주의해야 한다.
Max norm constraints
- weight vector에 upper bound를 설정하는 것이다. (미분값도 제한된다.)
- learning_rate를 크게 잡더라도 explode 하지 않는다.
Dropout
- 위에서 소개한 정규화 방법들과 같이 사용할 수 있다. random 하게 hidden node와 input node를 제거하고(off하고) 이들은 weight를 업데이트 하지 않는다.
- 이는 training 과정에서만 적용되고, prediction에서는 dropout을 사용하지 않는다.
Speed of Convergence
- batch training
- Momentum term
- weight initialization
- learning rate
- activation functions
- feature normalization and scaling
- batch normalization(BN)
일반적인 BP(backpropagation)은 saddle point나 local minimum에 약하다는 단점이 있다.
- momentum term
- gradient update에 관성을 부여한다는 아이디어다.
- 기존 BP는 다음 식에 따라서 업데이트 된다.
- momemtum term은 이전 weight update 한 값을 일부 제해서 더해준다.
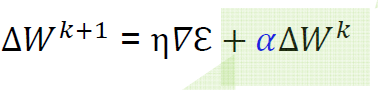
- a가 0이라면 일반적인 backpropagation과 동일하다.
- a가 1이라면 gradient descent는 완전히 무시되고, mometum에 의해서만 업데이트 된다.
- 보통 0.9나 0.95를 많이 사용한다.
- weight Initialization
- 초기에 weight를 어떻게 init하는지에 따라서 성능이 바뀐다. 적절한 값을 사용해야 한다.
- Xavier Initialization을 사용한다.
- Learning rate
- 적절한 learning rate를 골라야 한다.
- 너무 작게 고르면 늦게 수렴할 수 있다.
- 너무 크게 고르면 발산 할 수 있다.
- Adagrad, RMSprop, ADAM, ...
- 적절한 learning rate를 골라야 한다.
- Activation function
- simoid나 tanh같은 경우에는 미분값을 자주 곱할수록 작아지기 때문에 gradient vanishing 문제가 발생한다.
- 따라서 ReLU를 사용한다.
- 장점
- simple하고, positive region에서는 stable하다.
- 수렴속도도 따르다.
- sparsifcaiton을 허용한다.
- 단점
- gradient가 0보다 작은 값이 많다면 Dying 할수도 있다.
- Leaky ReLU, Parametric ReLU와 같은 걸로 해결 가능
- gradient가 0보다 작은 값이 많다면 Dying 할수도 있다.
- 장점
- Feature Normalization
- 각 feature들의 range가 다르기 때문에 normalization을 수행한다.
- Max-min normalization
- Z score normalization
- PCA - large dataset에는 부적합
- Batch Normalization (BN)
- 각 layer마다 input의 distribution이 달라지는 것을 막기 위함이다.
- pre-activation, post-activation에 각각 normalizing을 수행한다.
- 이는 mini-batch 단위로 수행히 가능하고, 각각 독립적으로 수행할 수 있다.
- prediction을 위해서는 re-adjust해야 하고, r과 b도 알아야 한다.
- 장점
- high learning rate가 가능하다.
- deep network에 사용 가능하다.
- weight init에 민감하지 않다.
- 단점
- Batch number가 커야 한다.
- dynamic network 구조나 recurrent network에 적합하지 않다.

Summary
- good convergence를 가장 우선적으로 생각해야 하지만 good generalization을 보장하진 않는다.
- convergence의 속도를 향상시키기 위해서 여러 방법들을 사용할 수 있다.
'Lecture Note > DeepLearning' 카테고리의 다른 글
| Lecture 3. Convolution Neural Network and its Variants (0) | 2021.06.30 |
|---|---|
| Lecture1. MLP and Backpropagation (0) | 2021.06.09 |