관계 데이터 모델에서 지원하는 언어에는 크게 두 가지가 있다.
1. 관계 해석 - 원하는 데이터만 명시하고 질의를 어떻게 수행할 것인가는 명시하지 않는 선언적인 언어
2. 관계 대수 - 어떻게 질의를 수행할 것인가를 명시하는 절차적 언어, SQL의 이론적인 기초
관계 대수
기존의 릴레이션들로부터 새로운 릴레이션을 생성한다. 즉 입력값, 출력 값이 모두 릴레이션이다.
연산자들을 적용하여 보다 복잡한 관계 대수식을 점차적으로 만들 수 있음. 기본적인 연산자들의 집합으로 이루어짐.
결과 릴레이션은 또 다른 관계 연산자의 입력으로 사용될 수 있다.
실렉션 연산자
σ<실렉션 조건>(릴레이션) 과 같이 사용하며 한 릴레이션에서 조건을 만족하는 투플들의 부분 집합을 생성한다.
단항 연산자이며 결과 릴레이션의 차수는 항상 입력 릴레이션의 차수와 같으며 카디날리티는 결과가 항상 작거나 같다.

프로젝션 연산자
π<애트리뷰트 리스트>(릴레이션) 과 같이 사용하며 한 릴레이션의 애트리뷰트들의 부분 집합을 구한다.
결과 릴레이션은 애트리뷰트 리스트에 명시된 애트리뷰트들만 가진다. 실렉션의 결과로는 중복 투플이 존재할 수 있지만 프로젝션의 결과에는 중복된 투플이 존재하지 않음


집합 연산자
릴레이션이 투플들의 집합이기 때문에 기존의 집합 연산이 릴레이션에 적용된다. 집합 연산자에는 합집합, 교집합, 차집합이 있다. 집합 연산자의 입력으로 사용되는 두 개의 릴레이션은 합집합 호환이어야 한다.
*합집합 호환
두 릴레이션 R1(A1, A2,..., An)과 R2(B1, B2,... , Bm)이 합집합 호환일 필요충분조건은 n=m이고, 모든 1 <=i <=n에 대해 domain(Ai)=domain(Bi)이다.
합집합 연산자
릴레이션 1 ∪ 릴레이션 2와 같이 사용하며 릴레이션1에 있거나, 릴레이션2에 있는 투플들로 이루어진 릴레이션을 반환
결과 릴레이션에서는 중복된 투플들은 제거한다.


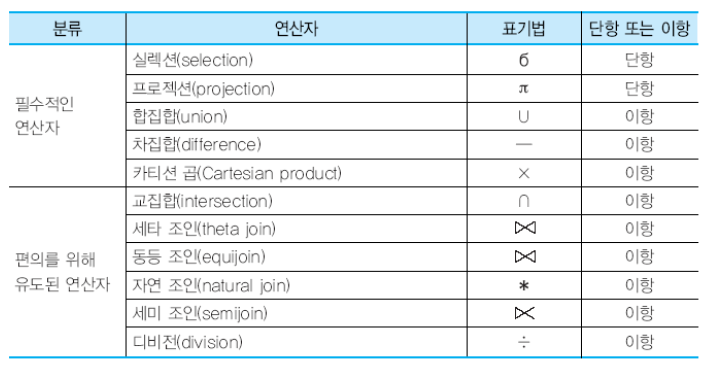
교집합 연산자
릴레이션1 ∩ 릴레이션2 와 같이 사용하며 릴레이션 1, 릴레이션 2에 동시에 속하는 투플들로 이루어진 릴레이션
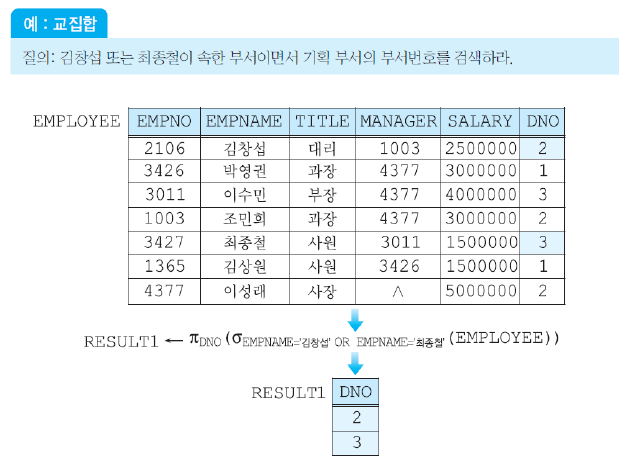

차집합 연산자
릴레이션 R, S에 대해 차집합 R-S는 R에는 속하지만 S에는 속하지 않은 투플들로 이루어진 릴레이션

'Lecture Note > DataBase' 카테고리의 다른 글
| [강의노트_DB]11. SQL-1 (0) | 2019.06.25 |
|---|---|
| [강의노트_DB]10. 관계 대수-2 (0) | 2019.05.09 |
| [강의노트_DB]8. 무결성 제약조건 (0) | 2019.05.02 |
| [강의노트_DB]7. 릴레이션의 특성과 키 (0) | 2019.04.30 |
| [강의노트_DB]6. 관계 데이터 모델 (0) | 2019.04.25 |