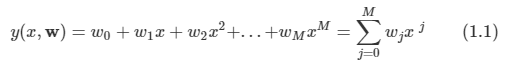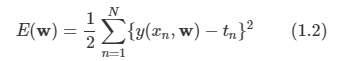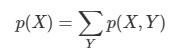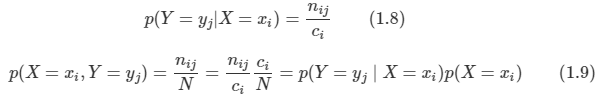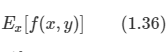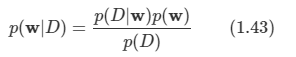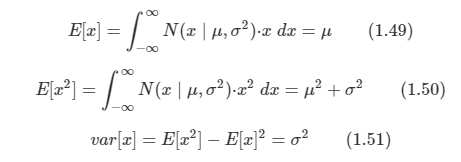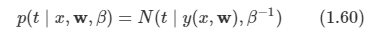케빈 머피의 Machine Learning 책을 보고 정리한 내용들입니다.
1.4 Some basic concepts in machine learning
이번 절에서는 머신 러닝에서의 주요 아이디어를 제공한다. 뒷 파트에서 더 자세히 다룰 예정이기 때문에 여기서는 간략하게만 다룬다.
1.4.1 Parametric vs non-parametric models
이 책에서는 지도 학습과 비지도 학습에 따라서 확률 모형을 다르게 구성한다. 이런 모형을 정의하는 많은 방법이 있지만, 가장 중요한 차이는 모형이 고정된 개수의 변수(Parametric)를 갖는지, 혹은 훈련 데이터의 양에 따라 개수가 증가하는지(non-parametric) 여부다. Parametric한 모형은 빠르게 사용할 수 있는 장점이 있지만 데이터분포에 대한 강한 가정(데이터 분포에 영향을 많이 받는다.)을 만들기는 어렵다. non-parametric하면 데이터 분포에 영향을 덜 받지만 계산적으로 다루기 어렵다.
1.4.2 A simple non-parametric classifier: K-nearest neighbors
non-parametric 분류기의 가장 간단한 예를 K nearest neighbor (KNN) 분류기다. 이것은 데이터 집하에서 테스트 입력 x에 가장 가까이 에 있는 K개의 포인트를 찾는 것이며, 각 클래스의 멤버가 얼마나 이 집합에 있는지 개수를 계산하고, 실험적 비율을 추정 값으로 반환한다.
1.4.3 The curse of dimensionality
KNN 분류기는 간단하며, 레이블된 훈련 데이터가 충분하게 있다면 잘 작동한다. 하지만 KNN 분류기의 주요 문제는 고차원의 입력에 대해서는 잘 작동하지 않는다는 점이다. 고차원에서 성능이 잘 나오지 않는다는 것은 curse of dimensionality(차원의 저주) 때문이다.
1.4.4 Parametric models for classification and regression
차원의 저주에 대항하는 주요 방법은 데이터 분포의 성질에 관한 가정을 만드는 것이다. 귀납적 편향성이라고 불리는 이 가정은 parametric한 모델로 구현하며, 고정된 개수의 매개변수를 가지는 통계 모형이다. 폭넓게 사용되는 두 가지의 예를 살펴본다.
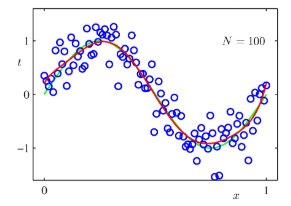
1.4.5 Linear regrssion
회귀에서는 선형 회귀(Linear regression)이라고 알려져 있는 것을 주로 사용한다. 이 모형에서는 입력에 대한 식을 1차 함수로 나타낸다. 다음과 같이 식을 표현한다.

여기서 x항은 입력벡터, w는 가중치 벡터라고 하며, 이들을 scalar 곱 형태로 나타낸다. 입실론 값은 선형 예측과 실제 응답 사이의 에러를 의미한다.
이 에러는 가우시안 또는 정규 분포를 갖는 것으로 가정한다. 선형 회귀와 가우시안과의 관계를 더 명시적으로 만들기 위해 다음의 형태로 모형을 다시 작성할 수 있다.
1.4.6 Logistic regression

앞서 본 선형회귀를 두 가지만 변경한다면 일반화할 수 있다. 첫번째는 선형 회귀에서는 가우시안 분포라고 가정했던 것을 베르누이 분포라고 가정한다. y의 값이 0과 1만을 가진다면 다음과 같이 분포를 정의한다.
두 번째는 이전과 같이 식을 계산한 뒤에 0과 1 사이의 값을 가질 수 있도록 보장하는 함수인 sigmoid를 적용한다. sigmoid는 다음과 같이 적용한다.
sigmoid는 위와 같이 그래프가 그려지고, 값을 0과 1 사이의 수로 매핑하기 때문에 확률의 값을 나타낼 때 주로 사용한다. 두 변경을 모두 적용하면 다음과 같은 식을 얻을 수 있다.
이 식은 선형 회귀와 유사하기 때문에 로지스틱 회귀 분석이라고 부른다.
1.4.7 Overfitting

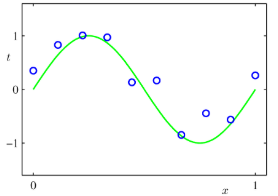
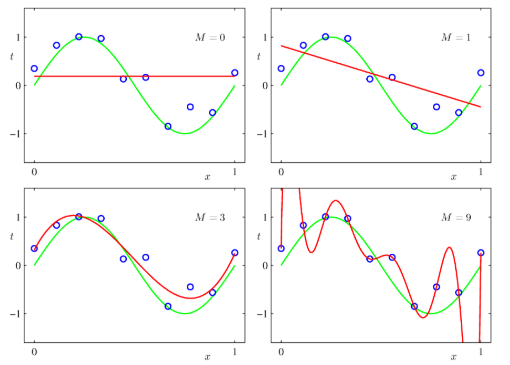
유연한 모델을 만들기 위해서 overfit(과적합)하지 않도록 주의해야 한다. 즉, 입력의 모든 변화를 모형화하는 것을 피해야 한다는 것으로, 이런 모형일 수록 노이즈인 경우가 많기 때문이다. 위와 같은 예시가 있을 수 있다. (b)가 모든 변화를 모형화를 한 경우에 해당된다. 하지만 실제 함수가 예시와 같이 생긴 확률을 낮기 때문에, 이런 모형을 사용해서 예측을 하는 경우 부정확한 결과를 얻을 수 있다.
1.4.8 Model selection
생략
1.4.9 No free lunch theorem
대부분의 머신 러닝의 알고리즘은 새로운 모델을 만들거나, 그것들이 적합하도록 만드는 것에 관심이 있다. 특정 문제에 대해서 최적화할 수 있지만, 모든 문제에 대해 최적의 모델은 없다. 이것을 No free lunch theorem 라고 한다. 하나의 영역에서 잘 작동하는 가정이 다른 영역에서 잘 작동하는 가정이 다른 영역에서 잘못 작동하는 경우가 있다.
'Book > Machine Learning' 카테고리의 다른 글
| [Machine Learning]2. Probability - part. 1 (0) | 2022.03.09 |
|---|---|
| [Machine Learning]1. Introduction- part.1 (0) | 2022.02.17 |
| [ML]12. Continuous Latent Variable - part1 (0) | 2020.03.02 |
| [ML]ch 9.Mixture models and EM (0) | 2020.02.24 |
| [ML]ch 4. Linear Models for Classification - part 2 (0) | 2020.02.17 |