아래 모든 내용들은 Christopher Bishop의 pattern recognition and machine learning에서 더 자세히 볼 수 있습니다.
Mixture models and EM
- 관측 변수와 잠재 변수들에 대한 결합 분포를 정의한다
- 그러면 이에 해당하는 관측변수들만의 분포는 주변화를 통해서 구할 수 있다.
- 복잡한 관측 변수들에 대한 주변 분포를 상대적으로 더 다루기 쉬운 관측 변수와 잠재 변수 확장 공간상의 결합 분포를 통해서 표현할 수 있도록 한다.
- 잠재 변수를 도입하면 단순한 원소를 복잡하게 만들 수 있다.
- 혼합 모델은 clustering에서도 사용가능하다.
- 대표적으로 K-means 알고리즘이 있다.
- 일반적인 혼합 모델에서 가장 많이 사용하는 알고리즘인 EM알고리즘에 대해서 알아본다.
K-means clustering
- 다차원 공간 데이터 포인트들에서 해당 데이터들이 어떤 군집에 해당하는지 알아내는 작업을 수행한다.
-
데이터 집합 (x1,...,xN)를 고려하자.
-
이는 D차원을 가지며 K개의 집단으로 나눈다.
-
μk는 k번째 클러스터의 중심을 나타내는 값이라고 하자.
- 각각의 데이터 포인트로부터 가장 가까운 μk까지 거리의 제곱합들이 최소가 되도록 하는 것이 목표다.
-
-
데이터 포인트들을 집단에 할당하는 것을 설명하는 표현법을 정의한다.
- 변수 rnk ∈ 0,1을 정의한다.
- 만약 xn이 집단 k에 할당된다면 rnk=1이며 아닌 경우는 0이라 한다.
- 이를 one hot encoding이라 한다.
-
목적 함수를 정의한다. 이를 distortion measure(뒤틀림 척도)라고도 부른다.

-
이는 같은 클러스터에 속하는 각각의 점들로부터 그 클러스터의 평균과의 거리의 합을 제곱한 함수를 뜻한다.
-
이제 여기서 rnk, μk를 구해야 한다.
- 물론 J의 값이 최소가 되어야 한다.
- 반복적인 절차를 통해서 이를 해결하는 방법을 알아본다.
-
rnk 와 μk 를 구하기 위해 크게 2개의 단계로 나누게 된다.
- 먼저 μk의 임의의 초기값을 설정한다.
- 첫 번째 단계에서는 이 μk 값을 고정한 채로 J를 최소화하는 rnk 값을 구한다.
- 두 번째 단계에서는 rnk를 고정하고 μk를 구한다.
- 값이 수렴할 때까지 이 두 단계의 최적화 과정을 반복하게 된다.
- 각각의 두 단계를 E(expectation, 기댓값) 단계와 M(maximization, 최대화) 단계로 이를 합쳐 EM 알고리즘이라고 부른다.
- 이제 E,M을 이용한 K-means 알고리즘을 알아본다.
-
rnk를 구하는 과정을 알아본다.
-
J가 rnk에 대한 선형 함수이므로 쉽게 최적화 할 수 있고, 닫힌 형태의 해를 얻을 수 있다.
-
서로 다른 n에 해당하는 항들은 각자가 독립적이므로 각각의 n에 대해서 따로 최적화가 가능하다.
-
각 클러스터 중심과 데이터 포인트들의 거리를 측정해서 가장 가까운 클러스터를 선택한다.

-
-
이제 μk를 구해보도록 한다. 물론 rnk는 고정한다.
- 목적 함수 J는 μk에 대해서 제곱 함수이므로 미분을 통해 최솟값이 되는 지점을 얻을 수 있다.

-
이 식을 μk에 대해 풀면 다음과 같다.
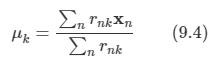
- 이 식의 분모는 집단 k에 할당된 포인트들의 숫자에 해당한다. 결국 집단 k에 할당된 모든 데이터 포인트들의 평균이라는 것이다. 따라서 이러한 이유로 이 과정을 K -means 알고리즘이라 한다.
-
그림을 통해서 K-means가 수렴하는 과정을 살펴보도록 한다.

-
그림으로 보면 쉽게 이해 할 수 있다.
- 우선 K=2로 설정을 하였고, (a)에서 임의의 μk 두 개를 설정한 것을 알 수 있다.
- (b)과정에서 두 개의 평균 값을 이용해서 E 과정을 거쳤고, (c)에서 M 과정을 거친다.
- 계속해서 EM 과정을 반복하고, 수렴 조건이 만족할 때까지 반복한다.

-
위 그림은 EM 과정을 반복할 때마다 목적 함수 J의 값이 줄어드는 것을 나타내는 단계이다.
-
각 단계에서 J의 값이 감소하기 때문에 수렴은 보장되어 있지만 전역 최솟값으로 간다는 보장은 존재하지 않는다.
-
평균 μk의 초기 값이 어디에 위치하는지에 따라 성능의 차이가 발생한다.
- 실제 반복 횟수의 차이가 발생하게 된다.
- K-means 알고리즘은 유클리드 거리를 사용하고 있기 때문에 매우 느릴 수 있다.
- 따라서 이를 빠르게 하는 방법들이 있다.
- 서로 근접한 포인트들이 같은 서브트리에 속하게 하는 방식의 트리와 같은 데이터 구조를 미리 계산한다.
- 삼각 부등식을 사용해서 불필요한 거리 계산을 줄인다.
- K-means 알고리즘은 모든 데이터 포인트들과 평균 간의 유클리드 거리를 계산해야 하기 때문에 느릴 수 있다.
- 따라서 유클리드 거리를 사용할 수 있어야 하고, outlier에 영향을 많이 받는 알고리즘이다.
- 따라서 이러한 문제를 해결할 수 있도록 k-medoids 알고리즘, 중간값을 활용하도록 한다.
k-medoids 알고리즘
-
유클리디안 거리 측정 대신 v(x,x')를 정의해서 사용한다.
-
목적 함수는 다음과 같다.

-
E 단계은 앞서 살펴본 방식과 동일한 방법으로 O(NK)가 된다.
-
M 단계는 이전보다 더 복잡할 수 있다.
- v 의 비용이 이전보다 커지게 되고, 연산량을 줄이기 위해서 중심점을 클러스터에 속하는 데이터 중 하나로만 선정하기도 한다.
- 이 경우 O(Nk2)의 비용이 필요하게 된다.
- K-means 알고리즘은 모든 데이터 포인트들이 정확하게 단 하나의 집단에만 할당된다.
- 하지만 가끔 모두 비슷한 거리에 위치에 어디에 속하게 해야 할지 애매할 수 있다.
- 이러한 경우 확률적인 접근 방식을 이용하여 특정 클러스터에 대한 할당을 클러스터에 포함될 확률값으로 결정할 수 있다.
혼합 가우시안
-
앞서 가우시안 성분들을 선형으로 중첩시킨 가우시안 혼합 모델을 사용하면 단일 가우시안을 사용할 때보다 더 다양한 종류의 밀도 모델들을 표현할 수 있다.
-
이번 절에서는 이산 잠재(latent) 변수들을 이용해서 혼합 가우시안 모델을 만든다.
-
가우시안 혼합 분포를 다음과 같이 선형 중첩 형태로 적을 수 있다.

-
이제 K차원을 가지는 이산 확률 변수 z를 도입한다. 이 변수는 특정 원소 zk는 1이고 나머지는 0인 one-hot encoding 방법을 사용한다.
-
결합 분포는 다음과 같이 정의 한다.
-
p(x,z)=p(z)p(x|z)

-
이제 zk의 주변 분포를 혼합 계수 πk를 사용하여 정의한다.

-
매개변수 πk는 다음의 두 제약 조건을 만족해야 한다.

-
또한 z가 one-hot-encoding을 사용하므로 이 분포를 다음의 형태로 적을 수 있다.
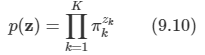
-
-
이와 비슷하게 특정 z 값이 주어졌을 때의 x에 대한 조건부 분포는 다음 형태의 가우시안 분포다.

-
이는 다음의 형태로 적을 수 있다.
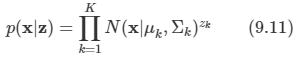
-
결합 분포는 p(z)p(x|z)의 형태로 주어진다. 이때 모든 가능한 z의 상태에 대한 결합 분포를 합산함으로써 x의 주변 분포를 구할 수 있다.
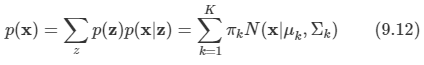
- x의 주변 분포는 식 9.7 형태의 가우시안 혼합 분포가 된다. 여러 개의 값 x1, ... xN을 관측했을 경우, 주변 분포를 p(x)의 형태로 표현했기 때문에 모든 관측된 데이터 포인트 xn에 대해서 해당 잠재 변수 zn이 존재한다.
- 명시적으로 잠재 변수를 사용하는 가우시안 혼합 분포를 보았다.
- 이 결과로 주변 분포 대신에 결합 분포를 직접 활용할 수 있다.
- 이것이 계산 과정을 매우 단순하게 만들어 준다.
- x가 주어졌을 때의 z의 조건부 확률을 구하는 것도 중요하다. 그 확률은 다음과 같이 정의하도록 한다.
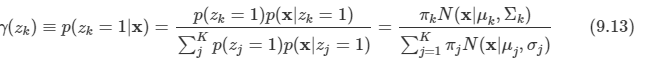
- 우리는 πk가 zk=1일 때의 사전 확률 값이라는 것을 안다.
- 이제 γ(zk)는 관찰 데이터 x가 주어졌을 때의 사후 확률 값이 된다.
- 이를 성분 k에 대한 responsibility라고 한다.
-
ancestral sampling를 통해서 가우시안 혼합 모델에 부합하는 random 표본을 추출해 내는 것이 가능하다.
- 이를 위해서 z 값 하나를 주변 분포 p(z)에서 추출하여 z_hat이라고 한다.
- 조건부 분포 p(x|z_hat)로부터 x 값을 추출한다. 정확한 내용은 11장에서 소개한다.

-
결합 분포로부터의 표본들은 (a)에 해당한다. 여기서 x 값에 해당하는 포인트들을 그리고 이에 대한 해당 z 값에 따라 그 포인트를 색칠(빨강, 초록, 파랑)하는 방식을 사용했다.
- 어떤 가우시안 성분이 x 값을 만들어 낸 책임이 있는지 표현할 수 있다.
-
주변 분포 p(x)로부터 표본들은 z 값을 무시하고 결합 분포에서 표본들을 추출해서 생성할 수 있고 이는 (b)에서 표시되어 있다.
-
데이터 포인트 각각에 대해서 데이터 집합이 생성된 혼합 분포의 각 성분에 대한 사후 분포를 구하는 방식을 이용하면 합성 데이터를 이용해 책임 정도를 표현할 수 있다.
- 즉 각 색의 비율로 표현할 수 있고, (c)에 표현되어 있다.
-
(a)와 같은 결과를 complete하다고 표현하고, (b)와 같은 경우엔 imcomplete 하다고 표현한다.
9.2.1 최대 가능도 방법
-
관찰 데이터가 x1,...,xN으로 주어져 있다.
-
이 데이터 집합은 N x D 행렬 X로 표현한다. (N은 sample 수,D는 한 sample의 차원)
-
이와 비슷하게 해당 잠재 변수들은 N x K 행렬 Z로 표현할 수 있다.
-
모든 데이터가 독립이라고 가정하면 그래프를 이용해서 표현할 수 있다.

-
이제 로그 가능도 함수는 다음과 같이 주어진다.

-
-
MLE를 통해 이 함수를 최대화하기 위해 발생하는 문제들에 대해 알아본다.
특이점(singularity) 문제
-
공분산 행렬이 Σk=σ2kI 인 가우시한 혼합 모델을 고려한다.
-
j번째 성분이 평균으로 μj를 가지며, 이것이 데이터 포인트들 중 하나의 값과 정확히 일치한다고 하자.
- μj=xn이다.
-
이 데이터 포인트는 가능도 함수 식의 항에 다음과 같이 기여한다.
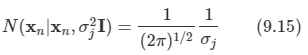
-
만약 σj가 0으로 간다면 무한대의 값을 가지게 될 것이고, 로그 가능도 함수를 최대화하는 것은 적절하지 않다.
- 이러한 특이점들은 항상 존재하고, 하나가 문제가 발생해도 이러한 문제는 발생할 수 있다.
-
하지만 단일 가우시안 분포의 경우에는 문제가 없었다.
- 하나의 위치로 거의 수렴하는 단일 가우시안 모델은 평균 값 외에는 밀도 값이 0이 된다.
- 곱 인자에 기여하게 되므로 전체 가능도 함수값이 0 값을 가지게 될 것이다.
- 따라서 모든 데이터 포인트들에 유한한 확률을 부여할 수 있게 된다.
-
사실 MLE 방식은 오버 피팅 문제가 존재하는데 베이지안 접근법을 활용하면 이러한 문제가 발생하지 않는다.
-
평균값을 임의로 선택한 값으로 설정하고, 공분산값을 임의의 큰 값으로 설정한 후 계산을 진행하는 방식을 사용한다.
식별 문제(identifiability)
- 최대 가능도 해에 대해서 K!개의 동일한 해가 존재할 것이다.
- K개의 매개변수들을 K개의 성분들에 할당하는 K!개의 서로 다른 방법들이 있다.
이 문제는 12장에서 더 자세히 다루도록 한다.
9.2.2 가우시안 혼합 분포에 대한 EM
-
잠재 변수를 포함한 모델의 최대 가능도 해를 찾기 위한 좋은 방법 중 하나는 EM 알고리즘이다.
-
우선 가우시안 혼합 모델의 맥락에서 약식으로 EM 알고리즘을 살펴보도록 한다.
-
가능도 함수의 최댓값에서 만족되어야 하는 조건들을 적는 것으로 논의를 해본다.
-
식 9.14를 가우시안 성분의 평균 μk에 대해 미분한 값을 0으로 설정하면 다음을 얻게 된다.

-
-
양변에 Σk를 곱하고 전개하면 다음을 얻게 된다. (이 때 행렬이 정칙이라고 가정한다.==역행렬이 존재한다.)

-
Nk는 집단 k에 할당되는 유효 데이터 포인트의 숫자로 해석한다.
-
수식을 자세히 살펴보면 사실 k번째 가우시안 성분의 평균은 데이터 집합의 모든 포인트들의 가중 평균으로 구할 수 있다.
- 이때 데이터 포인트 xn에 대한 가중치는 xn을 생성하는 데 있어서 성분 k의 책임 정도에 해당하는 사후 확률로 주어진다.
-
위와 동일하게 Σk에 대한 미분값을 0으로 놓고 단일 가우시안 공분산 행렬에 대한 해를 바탕으로 비슷한 추론 과정을 거치면 다음과 같다.

-
이는 데이터 집합에 근사한 단일 가우시안 분포의 경우와 비슷하다.
- 다른점은 각각의 데이터 포인트들이 해당 사후 확률로 가중되며, 해당 성분에 연관된 유효 데이터 포인트의 숫자가 분모에 추가된다는 점이다.
-
마지막으로 πk에 대해 최대화를 해보도록 한다. 이 때에는 이 값들의 합이 1이어야 한다는 제약 조건식을 생각해야 한다. 따라서 라그랑주 승수법을 사용하도록 한다.
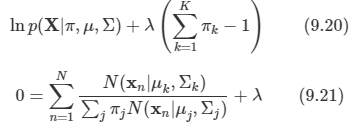
-
양변에 πk를 곱하면 γ(znk)가 나오게 된다. 이를 다시 정리하면 다음과 같다.

-
결국 k번째 성분의 혼합 계수는 데이터 포인트들을 설명하기 위해 취한 responsibility를 평균한 값이 된다.
-
이렇게 얻은 평균, 분산, 혼합 계수는 닫힌 형태의 해를 제공하지 못하는데, γ(znk)들이 복잡한 방식으로 종속되어 있기 때문이다.
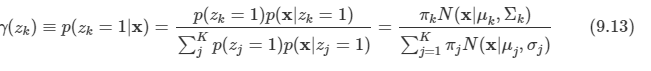
EM 알고리즘 적용

- EM 알고리즘은 반복적인 방법을 이용하여 값을 추정하는데, GMM에서는 다음과 같이 처리한다.
- (a)와 같이 random한 값으로 평균, 분산을 초기화 한다.
- E 단계
- 현재 값을 사용하여 사후 확률 z를 추정한다. -> (b)
- M 단계
- E 단계에서 계산한 값을 이용하여 MLE를 통해 평균, 분산, 혼합 계수의 값을 다시 추정한다. -> (c)
- 반복
- 수렴 조건이 만족할 때까지 E, M을 반복 (d) , (e) , (f)에 해당한다.
- EM 알고리즘이 수렴을 달성하기 위해 필요로 하는 반복 횟수가 K-means 알고리즘에 비해 훨씬 많다.
- 따라서 K-means 알고리즘을 먼저 수행해서 적합한 초기값을 찾아내고, EM 알고리즘을 적용하는 것이 일반적이다.
- K-means와 동일하게 특이점 문제가 발생하지 않도록 조심해야 한다.
- 여러 개의 지역적 최댓값이 있으므로 EM 알고리즘은 이들 중 가장 큰 값을 찾는 것을 보장하지 못한다.

'Book > Machine Learning' 카테고리의 다른 글
| [Machine Learning]1. Introduction- part.1 (0) | 2022.02.17 |
|---|---|
| [ML]12. Continuous Latent Variable - part1 (0) | 2020.03.02 |
| [ML]ch 4. Linear Models for Classification - part 2 (0) | 2020.02.17 |
| [ML]ch 4. Linear Models for Classification - part 1 (0) | 2020.02.10 |
| [ML]ch 3. Linear Models for Regression (0) | 2020.02.03 |