케빈 머피의 Machine Learning 책을 보고 정리한 내용들입니다.
1.1 Machine Learning: what and why?
현재 우리는 빅데이터 시대에 살고 있으며, 수많은 양의 정보들을 마주하고 있다. 이러한 데이터들을 분석하기 위해 자동화된 데이터 분석 기법이 필요하게 되었고, 머신 러닝이 이러한 역할을 수행할 수 있다. 머신 러닝은 데이터의 패턴을 자동으로 인지하고, 다뤄지지 않은 패턴을 사용해 미래의 데이터를 예상하거나 불확실성 아래서 여러 종류의 결정을 선택하는 방법이다.
1.1.1 Types of machine learning
머신 러닝은 보통 두 개의 타입으로 구분할 수 있다.
- Predictive, supervised learning
- 레이블이 있는 입출력의 쌍이 주어졌을 때, 입력 x로 출력 y를 매핑하는 함수를 학습하는 것이 목표
- 입력 x는 D차원 벡터로서 특징(feature), 속성(attribute), 공변량(covariance)라고 한다.
- 출력 y는 한정된 값을 가지는 범주형 변수, 실수 값을 가지는 스칼라 변수가 있을 수 있다.
- y가 범주형인 경우 분류(classification), 실수인 경우는 회귀(regression)이라고 한다.
- Descriptive, unsupervised learning
- 해당 방법에서는 입력만이 주어지고, 데이터 내의 흥미있는 패턴(interesting pattern)을 찾는 것이다.
- 찾고자 하는 패턴이 주어지지 않기 때문에, 정의가 불분명하고, 에러를 측정할 수 있는 명확한 방법이 없다.
- Reinforcement learning
- 보상(reward)이 주어질 때 동작이나 행동을 배울 때 유용하다.
- RL에 대해서는 이 책에서 자세히 다루지 않도록 한다.
1.2 Supervised learning
1.2.1 Classification
Classification의 목적은 입력 x로부터 출력 y를 매핑하는 것을 학습하는 것으로, y는 1~C의 값을 가지며, C는 class의 갯수를 의미한다. C=2인 경우에는 binary classification이라 하고, C > 2는 multiclass classification이라고 한다.
훈련 데이터에 대해서 학습을 하고 예측을 하는 것을 쉽기 때문에 classification의 주요 목적은 전에 보지 못했던 데이터들에 대해서도 답을 정확하게 예측하는 것(Generalization)이다.
1.2.1.2 The need for probabilistic predictions
주어진 입력 벡터 x와 훈련 집합 D에 대해 가능한 레이블들의 확률 분포를 나타낸다. 일반적으로 이 것은 길이가 C로 나타난다. 훈련 집합 D 뿐만 아니라 테스트 입력 x에 대한 조건부 확률이라는 것을 명시적으로 나타내기 위해 표기법에서 조건식 기호 | 의 오른쪽에 D와 x를 둔다.
확률적인 결과가 주어진다면, 다음의 식을 사용하여 레이블 값이 참인 경우에 대해 최선의 추측을 계산할 수 있다.
이 값은 가장 확률이 높은 클래스 레이블이고, 최대 사후 확률(MAP estimate) 로 알려져 있다. 해당 내용은 5.7에서 수학적인 검증을 한다.
다음과 같은 분야에서 실제로 응용되고 있다.
- 문서 분류와 이메일 스팸 필터링
- 꽃 분류
- 이미지 분류와 글씨 인식
- 얼굴 검출과 인식
1.2.2 Regression
Regression은 결과 변수가 연속적이라는 것을 제외하고 분류와 같다. 다음 그림은 단순한 예시를 보여준다.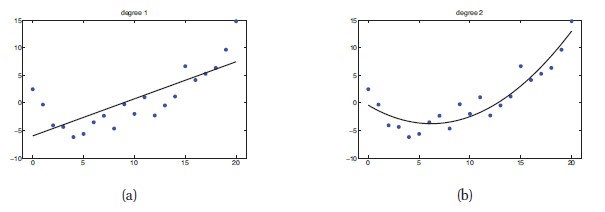
다음은 실생활에 존재하는 Regression 문제의 예다.
- 현재 시장 상황과 다른 가능한 정보를 통해 다음 날의 주식 시장을 예측하는 것
- YouTube를 보는 사용자의 나이 예측
- 날씨 데이터와 시간, 문의 센서를 통해 건물 안의 온도를 예측하는 것
1.3 Unsupervised learning
Supervised learning과는 다르게 각 입력에 대해 기대되는 출력이 주어지지 않는다. 대신 작업을 확률 밀도 추정의 하나로 공식화한다. 즉, p(x|theta) 형태의 모형을 설계하는 것이 목표다. 이 말은 Unsupervised learning은 비조건적인 밀도 추정 문제에 해당한다.
1.3.1 Discovering clusters
Unsupervised learning의 기본이 되는 예제로 데이터를 그룹으로 clustering하는 문제다. 아래 그림은 210명의 키와 몸무게 대한 데이터들이다. 여러 개의 클러스터나 하위 그룹이 있는 것으로 보인다. K가 클러스터의 숫자를 의미한다고 하면, 첫 번째 목표는 p(K|D)를 예측하는 것이다. Supervised learning에서는 남자/여자와 같은 클래스가 있지만 Unsupervised learning은 클러스터의 갯수를 자유롭게 설정할 수 있다.
두 번째 목표는 각 데이터가 어떤 클러스터에 속하는지를 추정하는 것이다.(b)는 K=2일 때의 결과에 해당한다.
이 책에서는 model based clustering에 초점을 맞춘다. 모형 기반 클러스터링은 객관적인 방법으로 여러 모형을 비교할 수 있고, 여러 모형을 더 큰 시스템으로 조합할 수 있다.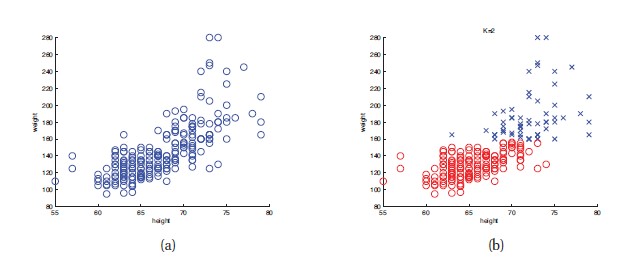
클러스터링의 실제 응용은 다음과 같다.
- 천문학에서 천제 물리학의 측정값을 클러스터링하여 새로운 타입의 별을 발견할 수 있다.
- e-커머스에서 구입 내역과 웹 서핑을 분석하여 사용자들을 분석할 수 있고, 각 그룹에 타켓팅한 광고를 설정할 수 있다.
1.3.2 Discovering latent factors
고차원의 데이터를 처리할 때에는 데이터의 'essence'을 가지고 있는 작은 차원의 부분 공간으로 사영시키는 것이 유용하다.이것을 차원 축소라고 부른다. 아래 그림은 간단한 예시로, 3차원의 데이터를 2차원 평면으로 투영한 것이다.
2차원 데이터로 투영한 (b)는 유사한 위치에 놓여 있는 것을 보아 결과가 좋게 나왔지만, 1차원으로 축소한 (a)의 빨간 선은 결과가 좋지 못하다. (해당 내용은 12장에서 더 자세히 다룬다.)
낮은 차원의 표현은 다른 통계 모형의 입력으로 사용하면 좀 더 예측 정확도가 높아진다. 이는 불필요한 특징을 거르기 때문이다. 차원 축소를 위한 가장 일반적인 접근은 주성분분석(Principal Componenet Analysis, PCA) 이다. 이는 linear regression의 비지도 버전과 같다. 고차원 응답 y를 관찰하지만, 저차원의 '원인' z는 발견하지 못한다. 이 모델은 z -> y 형태를 가지고 , 화살표를 뒤집어서 관찰된 고차원 y를 통해 잠재된 차원 z를 추정해야 한다.
1.3.3 Discovering graph structure
상관관계가 있는 변수를 측정하고, 가장 관련이 있는 것을 발견하려는 때가 있다. 이러한 구조는 그래프로 표현할 수 있다. 노드는 변수를 표현하고, 엣지는 변수 사이의 의존 관계를 표현한다.
1.3.4 Matrix completion
데이터가 손실되는 경우가 있다. 즉, 변수의 값을 모르는 경우가 발생할 수 있다. 따라서 이렇게 손실된 데이터에 타당한 값을 추정하는 것이며, 이것을 매트릭스 완성이라고 한다.
'Book > Machine Learning' 카테고리의 다른 글
| [Machine Learning]2. Probability - part. 1 (0) | 2022.03.09 |
|---|---|
| [Machine Learning]1. Introduction- part.2 (0) | 2022.03.02 |
| [ML]12. Continuous Latent Variable - part1 (0) | 2020.03.02 |
| [ML]ch 9.Mixture models and EM (0) | 2020.02.24 |
| [ML]ch 4. Linear Models for Classification - part 2 (0) | 2020.02.17 |